
2024-06-20
Hands-on with Vector Databases
In this post, we'll cover vector databases, their internals, use-cases and some hands-on exercises.
Hands-on with Vector Databases
In this post, we'll be covering vector databases, how they differ from traditional databases, a high level overview of their internals and use cases. We'll also be doing some hands-on exercises to understand how to:
- Prepare the dataset
- Ingesting into the vector database
- Querying
- Building a RAG (retrieval augmented generation) workflow
The code for this post can be found here. Please do give us a star or follow if it was useful for you.
Best practices that'll prove valuable in a production setting will also be covered.
Let's get right to it.
Contents
- What is a Vector database?
- Similarity Distance Measures
- Vector Search Index: HNSW
- Qdrant overview
- Querying Qdrant
- Hands-on exercises
- Conclusion
What is a Vector database?
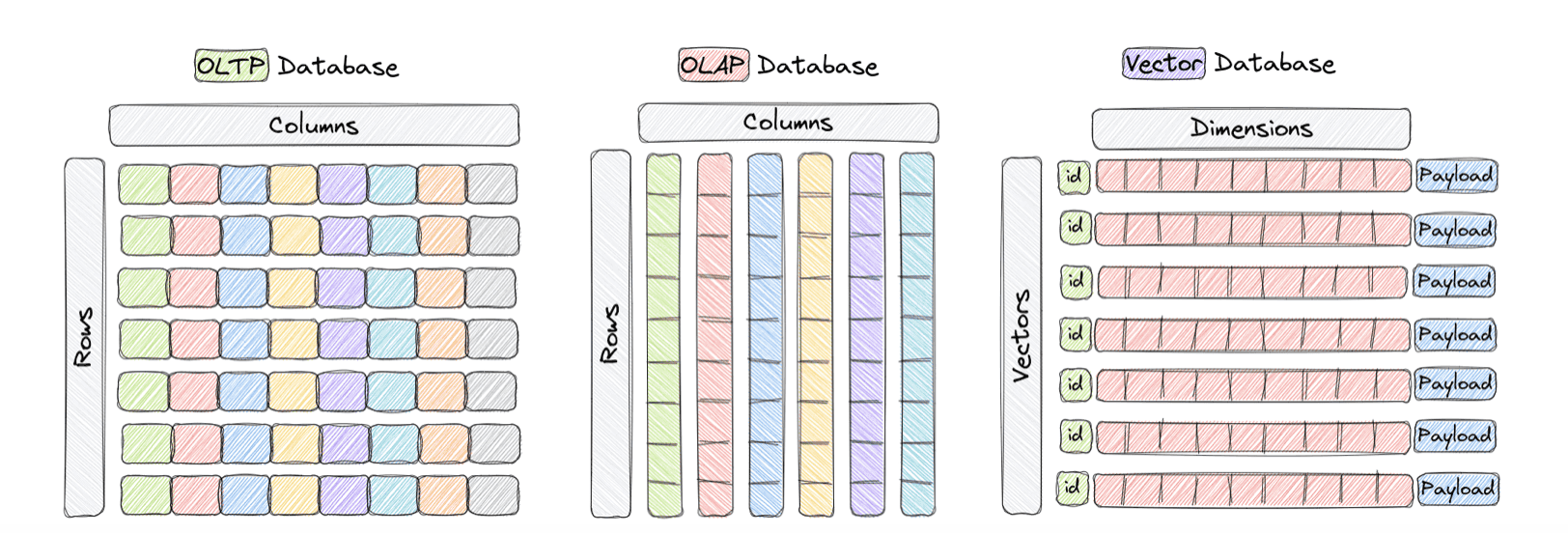
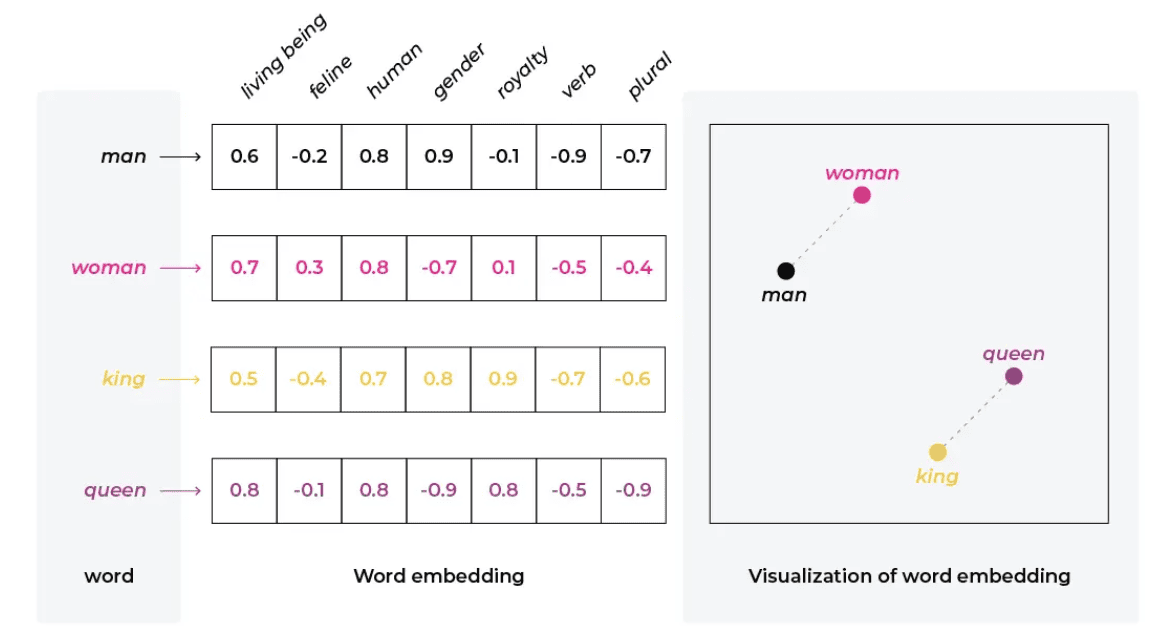
A vector database is a type of database optimised for handling vectors/embeddings which are numeric arrays. They're engineered to efficiently perform similarity search operations on high-dimensional data.
Source: Qdrant documentation
Unlike traditional databases that excel in match queries, vector databases shine in fuzzy searches based on similarity.
Source: Qdrant documentation
Some use cases for vector databases:
- Search Engines: Enhancing search results by finding similar items using vector comparisons
- Recommendation Systems: Powering user-tailored recommendations by comparing user and item vectors
- Natural Language Processing (NLP): Facilitating operations such as semantic search, text clustering, and language translation by comparing word or sentence embeddings
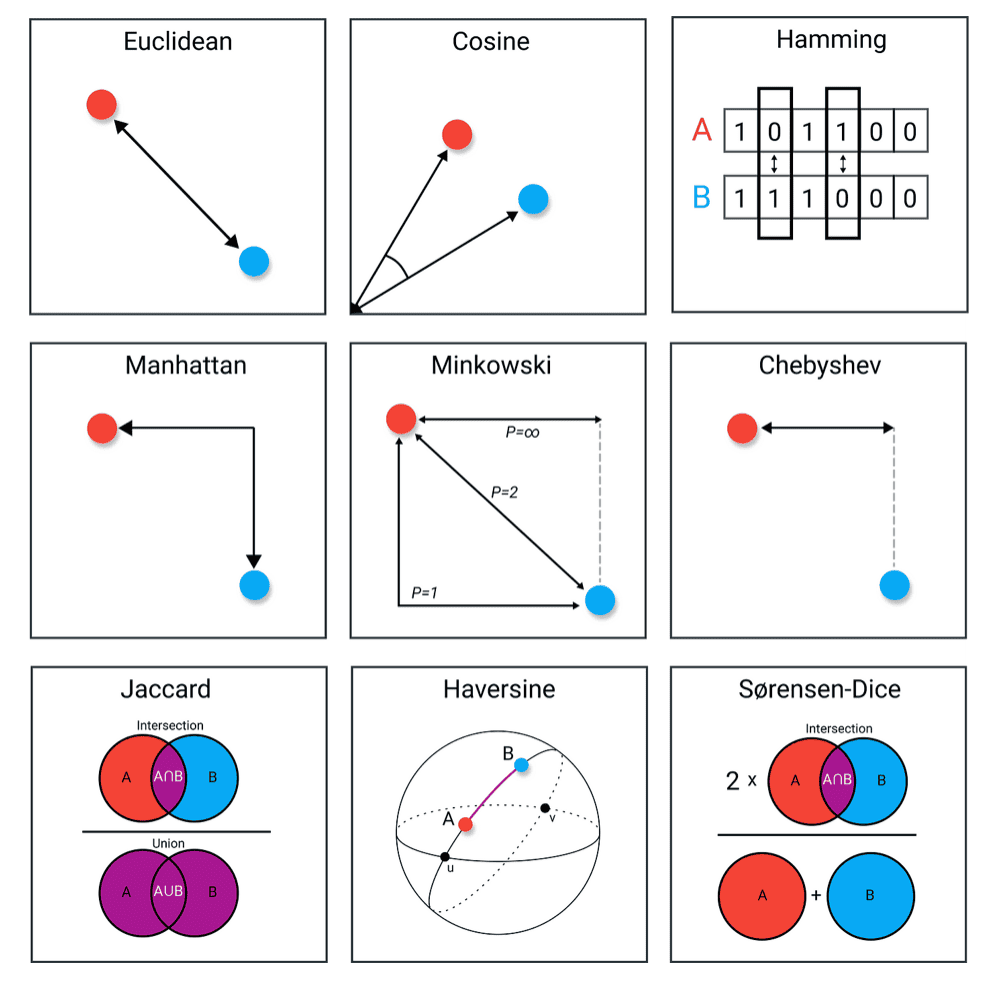
Similarity Distance Measures
Each object stored in the vector database is represented by a point in a high-dimensional space. There are different ways we can measure the similarity or distance between these points.
- Euclidean Distance: Measures the straight-line distance between 2 points
- Cosine Distance: Measures the cosine of the angle between the two vectors capturing their orientation rather than magnitude
- Manhattan Distance: Computes the sum of absolute differences between the components of the vectors (ex. Grid path-finding)
- Hamming Distance: Counts the number of positions at which vectors differ (suited for binary vectors)
- Jaccard Distance: Computes the similarity between sets (intersection over union)
Vector Search Index: HNSW
HNSW stands for Hierarchial Navigable Small Worlds. It is the top-performing index used for vector similarity search, in vector databases like Qdrant, Pinecone and others.
When we query a vector database, we retrieve a specific number of vectors that are the most similar to our query. The algorithm most commonly used for this is called KNN or K-nearest neighbors. However, this is resource intensive and the complexity scales linearly with the number of vectors in our database. In use-cases where we're optimizing for latency by trading off some minimal precision, most modern vector databases, implement the ANN algorithm (Approximate nearest neighbors).
HNSW is the most commonly used top-performing index for ANN. It is composed on two main components:
- Skip Linked List
- Navigable Small world graphs
Skip linked lists allow for fast search like a sorted array but using a linked list for fast insertion of new elements. It has multiple layers going from sparse from dense top-down.
The sparsity in the upper layers, allows it to skip over ranges and proceed to the next layer only when it has jumped ahead of the element we're searching for.
From the pinecone documentation:
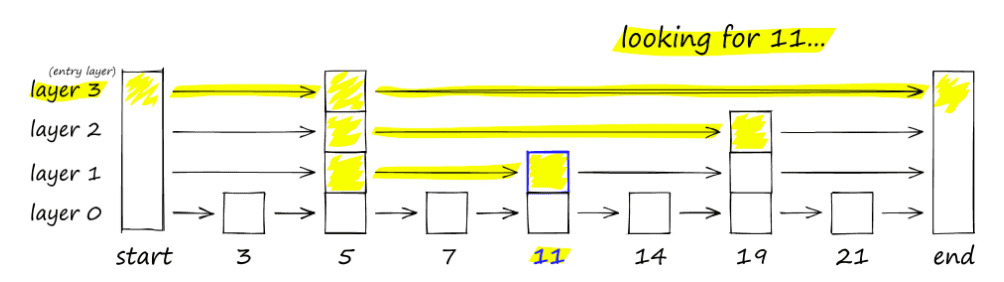
Source: Pinecone Documentation
Navigable small world (NSW) is a proximity graph that has both long-range and short-range links which has logarithmic search time. We enter the graph via a random entry point and traverse to the nearest vertex based on our query vector. This greedy search is repeated by navigation from vertext to vertex and we stop at the vertex whose neighbors are not as similar to the query as itself.
HNSW combines these two to form the vector space index. It is built as a multi-layered graph where each layer corresponds to different reolutions of the data. At each level, nodes are connected through short-range and long-range links, similar to skip linked lists. The navigable small world aspect comes into play with these links, creating a network where any node can be reached quickly from any other node, optimizing both the insertion of new vectors and searching them. This layered graph structure, where each layer is a navigable subset of data, allows for faster search at the cost of precision.
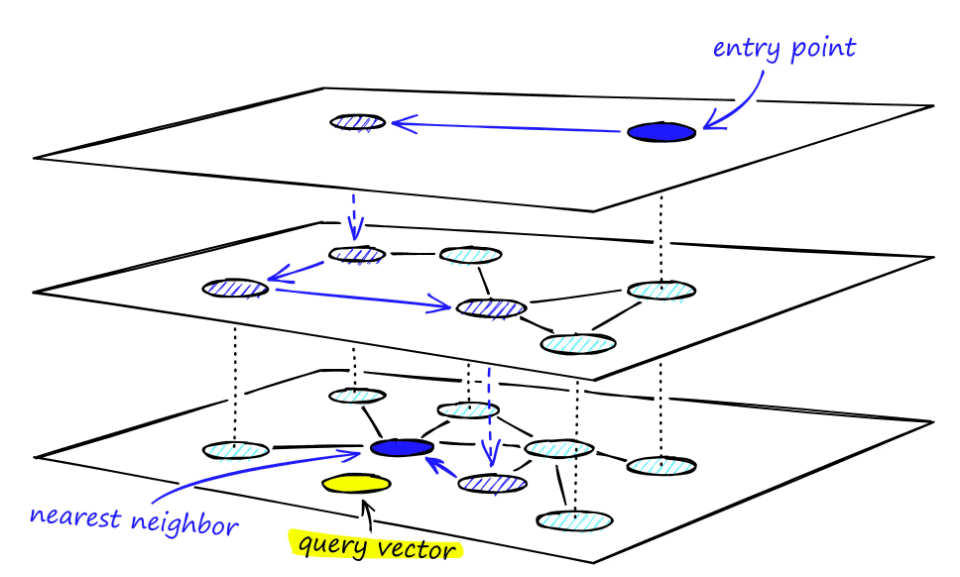
Source: Pinecone HNSW documentation
For more information about how the graph is constructed and searched, I recommend reading the excellent article from Pinecone.
The HNSW index has some factors that affect the index creation as well search:
-
M: The number of bi-directional links each element has to the other elements within the same layer. High values yield more accuracy but consume more memory and lead to longer indexing times.
-
ef(construction): Size of the dynamic candidate list during index construction, impacts index time and quality. Setting higher improves index quality but slower index times.
-
ef(search): Size of the dynamic candidate list while searching; impacts search-time and precision. Smaller values speed up query but at the cost of precision.
-
ml: Controls size of each subsequent layer, impacts index depth. Smaller values create more layers which can speed up searches but too many may not be efficient.
Qdrant overview
Now that we understand what vector databases are and how they work, we'll soon be getting into some hands-on exercises so we can cement our theoretical understanding.
We'll be using Qdrant as our vector database. It is a fast distributed vector database that provides a convenient API to store, search and manage vectors with additional payloads (key-value pairs). It is written in Rust and supports both in-memory and on-disk data structures for storing vectors, indices and payloads.
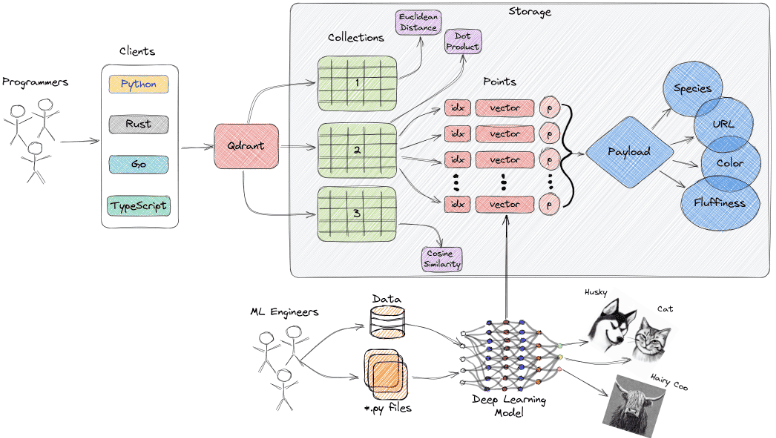
Source: Qdrant documentation
Some concepts in Qdrant:
- Collections are like tables in a relational DB. They are a named set of points.
- Points are like rows which consist of vectors and the payload associated with that vector.
- Querying is via the search API. We can specify the filter, query parameters, the vector and the number of neighbors to retrieve.
- Payload are the key-value pairs for a corresponding vector or point. It can represent some metadata about the vector and is generally used for filtering and augmenting the vector retrieved.
- Payload indexes can be created to speed up filtering by that payload. It improves query latency significantly for large collections.
Querying Qdrant
Query planning is done based on available indexse, filtering conditions and the cardinality of the filtering result.
Qdrant provides 3 main querying APIs:
- Search API
- Most common way to query either by vector or by a Point ID
- Can perform both exact KNN and ANN
- Also supports querying only indexed segments. Excludes segments where indexing is ongoing. Useful for scenarios where querying and ingestion is done at the same time. The tradeoff is eventual consistency.
- Batch Search API
- Multiple search requests in a single request
- Can be optimised by the query planner and reuse intermediate resutls across requests
- Pagination
- Extension to the search API
- Results can be paginated using the limit and offset search parameters
Hands-on exercises
Setup
-
Clone the repository. The
README.mdin the repository also details down the setup steps. You can follow those steps or continue here. -
Create a python virtual environment and install the dependencies.
1pip install poetry 2poetry install 3## activate the poetry env 4or
1# create an env using venv or conda 2pip install -r requirements.txt 3 -
Make sure you have docker installed on your machine. You can follow the steps here for your specific OS.
-
Spin up local qdrant on a docker container:
1docker-compose up -d 21version: "3" 2 3services: 4qdrant: 5 image: qdrant/qdrant 6 container_name: qdrant 7 volumes: 8 - qdrant-volume:/qdrant/storage 9 ports: 10 - "6333:6333" 11 12volumes: 13qdrant-volume: 14 -
Verify that the database is up and running
1curl localhost:6333/readyz 2You should get:
all shards are ready
About the dataset
We're simulating a dataset created from Confluence. A NEWS space exists in a sample Confluence setup and I've created a dataset for you to use in these exercises. There are around a 100 news articles in JSON format from topics like SCIENCE, SPORTS, BUSINESS etc.
Each JSON object has the following attributes:
id- the article IDspace- the topic of the articleurl- the URL where the article was publishedcontent- the headline or title of the article
However, feel free to experiment with creating your own dataset using the code under vectordb_blog/setup.
Pre-requisites
To proceed, you need:
- OpenAI credentials (I'm using Azure OpenAI here but feel free to change the environment variable to match your provider)
- Dataset under
data/confluence.json - Setup a
.envin the root of the project. You can use the.env.exampleas a template. These env vars are loaded into the config object.
Creating the Qdrant Collection
We'll be using the installed qdrant_client package to create the qdrant collection.
Initialize the client, create the collection and check if the collection already exists.
1qdrant_client = QdrantClient(url="localhost", port=6333, api_key=None) 2 3try: 4 qdrant_client.create_collection( 5 collection_name=config.QDRANT_COLLECTION_NAME, 6 vectors_config=models.VectorParams( 7 size=config.VECTOR_SIZE, 8 distance=models.Distance.COSINE 9 ) 10 ) 11except UnexpectedResponse as e: 12 print("Collection exists!") 13
We wrap the collection creation into a try except block to catch the qdrant_client.http.exceptions.UnexpectedResponse exception from Qdrant.
Next, we'll create the index on this collection as well. We create payload indexes on keys that we'll be using in our queries. In this case, we'll be filtering by the space key to get news by topic.
1qdrant_client.create_payload_index( 2 collection_name=config.QDRANT_COLLECTION_NAME, 3 field_name="space", 4 field_schema="keyword" 5) 6
Indexing documents into the collection
To index documents into the collection, we'll need to embed or convert the content key of our JSON document into a vector. We'll use the text-embedding-ada-002 model from OpenAI and theget_embedding() function defined under utils.
1def get_embedding(client: openai.AzureOpenAI, text: str) -> List[float]: 2 response = client.embeddings.create(model=config.MODEL_NAME, input=text) 3 return response.data[0].embedding 4
Our embedding model has a token size of 8192 tokens. Therefore, we'll chunk our content into multiple points before indexing them.
We'll read our file, line by line, parse the JSON, extract the content, chunk it by the token size of the model, turn it into a vector and finally index into Qdrant.
1for line in lines: 2 if line: 3 points = [] 4 page = json.loads(line) 5 content = page["content"] 6 chunks = batched(content, config.TOKEN_SIZE) # 8192 in our case 7 8 for chunk in chunks: 9 vector = get_embedding(openai_client, "".join(chunk)) 10 11 points.append( 12 models.PointStruct( 13 id=str(uuid.uuid4()), 14 vector=vector, 15 payload={ 16 "page_id": page["id"], 17 "space": page["space"], 18 "url": page["url"], 19 "content": "".join(chunk), 20 }, 21 22 ) 23 ) 24 25 for batch in batched(points, 20): 26 client.upsert( 27 collection_name=config.QDRANT_COLLECTION_NAME, 28 points=list(batch), 29 ) 30
We're setting the content in our payload, as Qdrant only retrieves similar vectors, we get the content the vector represents from the payload associated with it. Therefore, we've stored the content in the payload with the content key.
Querying the collection
We've already covered the capabilities of the Search API in Qdrant. We can provide provide filters for the query using the search API which improves the latency of our query by pre-filtering vectors.
Here, let's query the collection to get the latest news about the central bank interest rates in Europe.
1query = """ 2 Whats the latest on the central bank interest rates? 3""" 4 5vector = get_embedding(openai_client, query) 6 7 8results = client.search( 9 collection_name=config.QDRANT_COLLECTION_NAME, 10 query_filter=models.Filter( 11 must=[models.FieldCondition(key="space", match=models.MatchValue(value="BUSINESS"))] 12 ), 13 search_params=models.SearchParams(hnsw_ef=128, exact=False), 14 query_vector=vector, 15 limit=5, 16) 17 18
- First we embed the query using our embedding model so it can be represented in the same high dimensional space as the other vectors
- Next we use the
searchmethod of the Qdrant client to query the collection - We filter by the
spacekey and only match the points where the topic isBUSINESS - Optionally, we can provide search parameters for traversing the HNSW index. The
exactkeyword switches between KNN(exact=True) and ANN. Be mindful of the tradeoffs. - Lastly, we provide the query vector and the number of neighbors to retrieve.
RAG using Qdrant
Next, we'll construct a RAG (retrieval augmented generation) workflow to get answers summarized by an LLM.
RAG works by first retrieving the documents related to a query from a vector database. Once the similar documents are retrieved, it provides it as context and sends it to an LLM for summarisation.
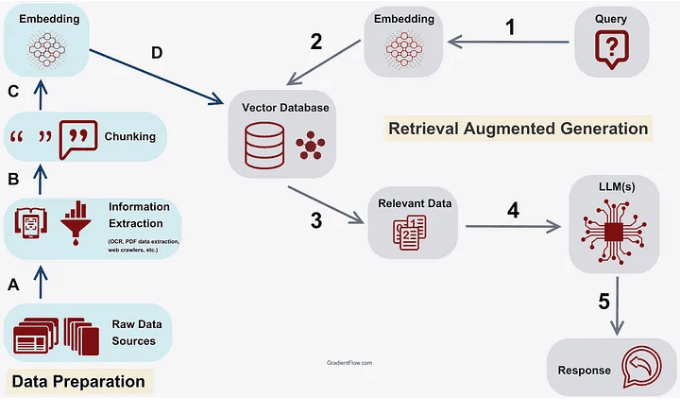
Source: Gradientflow documentation
A convenient way of building RAGs in python, is to use the Langchain framework. Comment below if you'd like us to create a hands-on post about Langchain.
In this post, we'll create a mini-RAG to query Qdrant for our document context and use OpenAI GPT 4 for the summarisation.
First, we initialize the model objects for the embeddings and for the LLM.
1# for embedding the query 2embeddings = AzureOpenAIEmbeddings( 3 model="text-embedding-ada-002-2", 4 azure_endpoint=config.OPENAI_ENDPOINT, 5 api_key=config.OPENAI_API_KEY, 6 api_version=config.OPENAI_API_VERSION, 7) 8 9# for summarizing 10llm = AzureChatOpenAI( 11 azure_endpoint=config.OPENAI_GPT_ENDPOINT, 12 azure_deployment=config.OPENAI_GPT_MODEL, 13 api_key=config.OPENAI_GPT_API_KEY, 14 api_version=config.OPENAI_API_VERSION, 15) 16
Next, we create a Qdrant client and create a document retriever. This essentially means that Langchain can use this retriever for extracting the most similar documents from the vector database for our queries.
1# to retrieve the documents from qdrant 2qdrant_client = QdrantClient(url="localhost:6333") 3vectorstore = QdrantWithPayload( 4 qdrant_client, 5 collection_name=config.QDRANT_COLLECTION_NAME, 6 embeddings=embeddings, 7 content_payload_key="content", 8) 9retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5}) 10
Since we want to summarise our response to the query, we'll use a prompt template for the LLM.
1template = """ 2Use the following pieces of context to answer the question at the end. 3If you don't know the answer, just say that you don't know, don't try to make up an answer. 4Always say "thanks for asking!" at the end of the answer. 5 6{context} 7 8Question: {question} 9 10Helpful Answer: 11""" 12 13rag_prompt = PromptTemplate.from_template(template) 14 15
Finally, we chain together all the components to form our RAG. It takes in a query/question, embeds it, retrieves similar documents from the vector database and sends them as context to an LLM. The LLM responds with a summarised answer following our instructions from the prompt template.
1rag = ( 2 { 3 "context": retriever | format_docs, 4 "question": RunnablePassthrough(), 5 } 6 | rag_prompt 7 | llm 8 | StrOutputParser() 9) 10 11 12answer = rag.invoke("Give me a summary of the top 10 news in technology.") 13 14 15print(answer) 16
Conclusion
Vector databases enable many generative AI use-cases. Some examples are semantic search, customer service Q&A and internal documentation chatbot.
I also help companies scale their AI infrastructure from experimentation to production-ready systems, and offer hiring advisory services to help you build teams that understand both the ML and infrastructure sides of AI applications.
If you have any suggestions, comments or corrections, please drop a comment down below.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.