
2024-12-17
Distributed Postgres Architectures
This is a series of blog posts about distributed data-intensive systems.
Distributed Data-Intensive Systems. Distributed Postgres Architectures
This is a series of blog posts about distributed data-intensive systems, what they are, how they're designed and the problems, trade-offs and optimizations in their context.
An excellent read on a more general overview of distributed systems and data-intensive applications can be found in the book by Martin Kleppmann.
Here is the entire series so far:
- Understanding Replication. Part-1
- Understanding Replication. Part-2
- Distributed Postgres Architectures (You're here)
- Leaderless Replication: Quorums, Hinted Handoff and Read Repair
Contents
Introduction
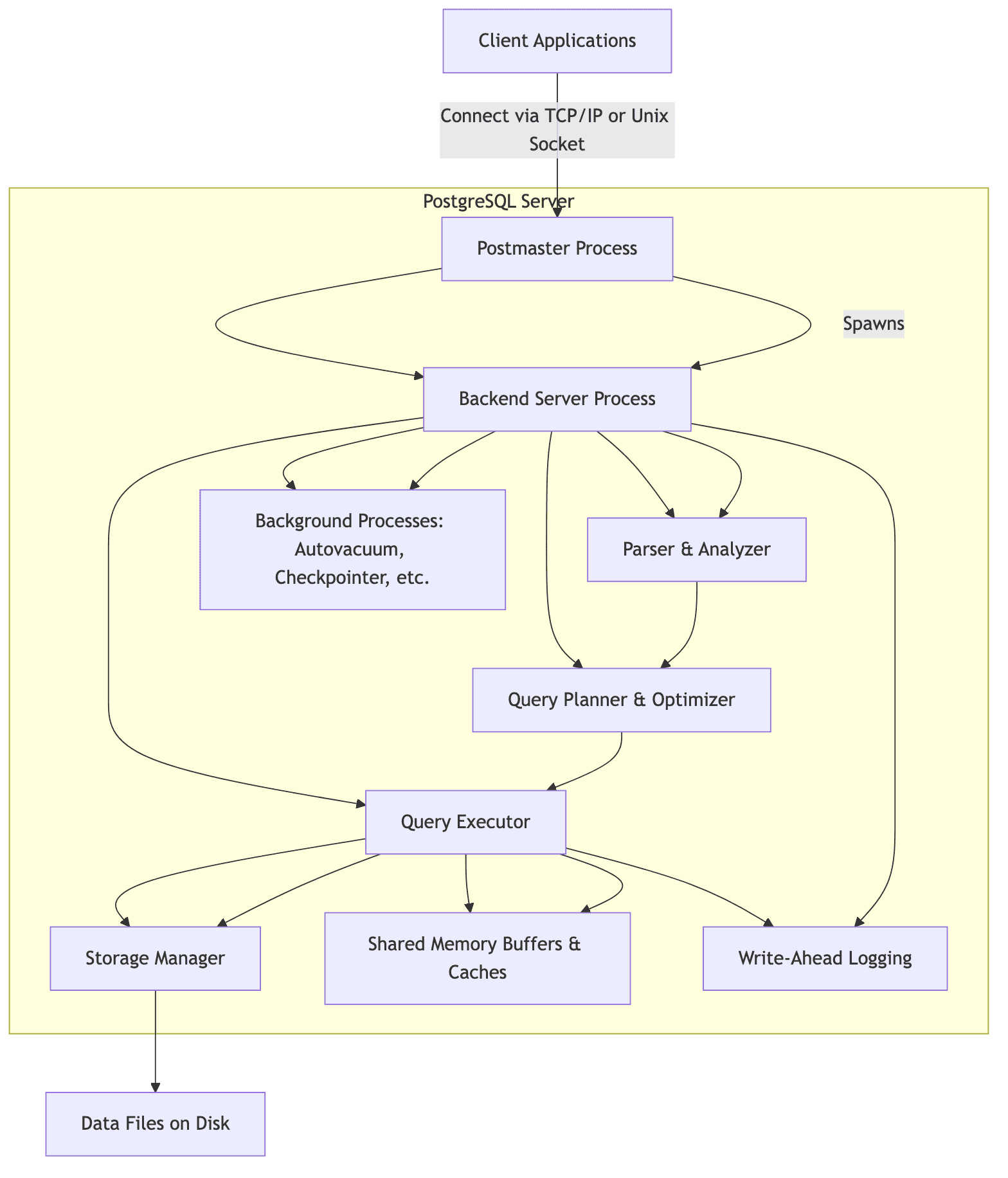
PostgreSQL is one of the most widely used relational database management system(RDBMS). It is open-source and emphasizes extensibility, standards compliance and robustness. Postgres' query execution flow involves several components. The parser converts SQL queries into an abstract syntax tree (AST), which is passed to the analyzer to validate semantics. The query planner/optimizer generates an optimal execution plan using statistics, indexes, and cost-based algorithms. The executor then processes the query by interacting with storage, retrieving, and modifying data as necessary.
PostgreSQL uses shared memory for buffers, locks, and caches to efficiently manage concurrent operations. It also employs Write-Ahead Logging (WAL) to ensure data durability and recovery in case of failures. The storage system comprises tables, indexes, and TOAST tables, which are managed within data files on disk, while background processes like the autovacuum daemon ensure database maintenance.
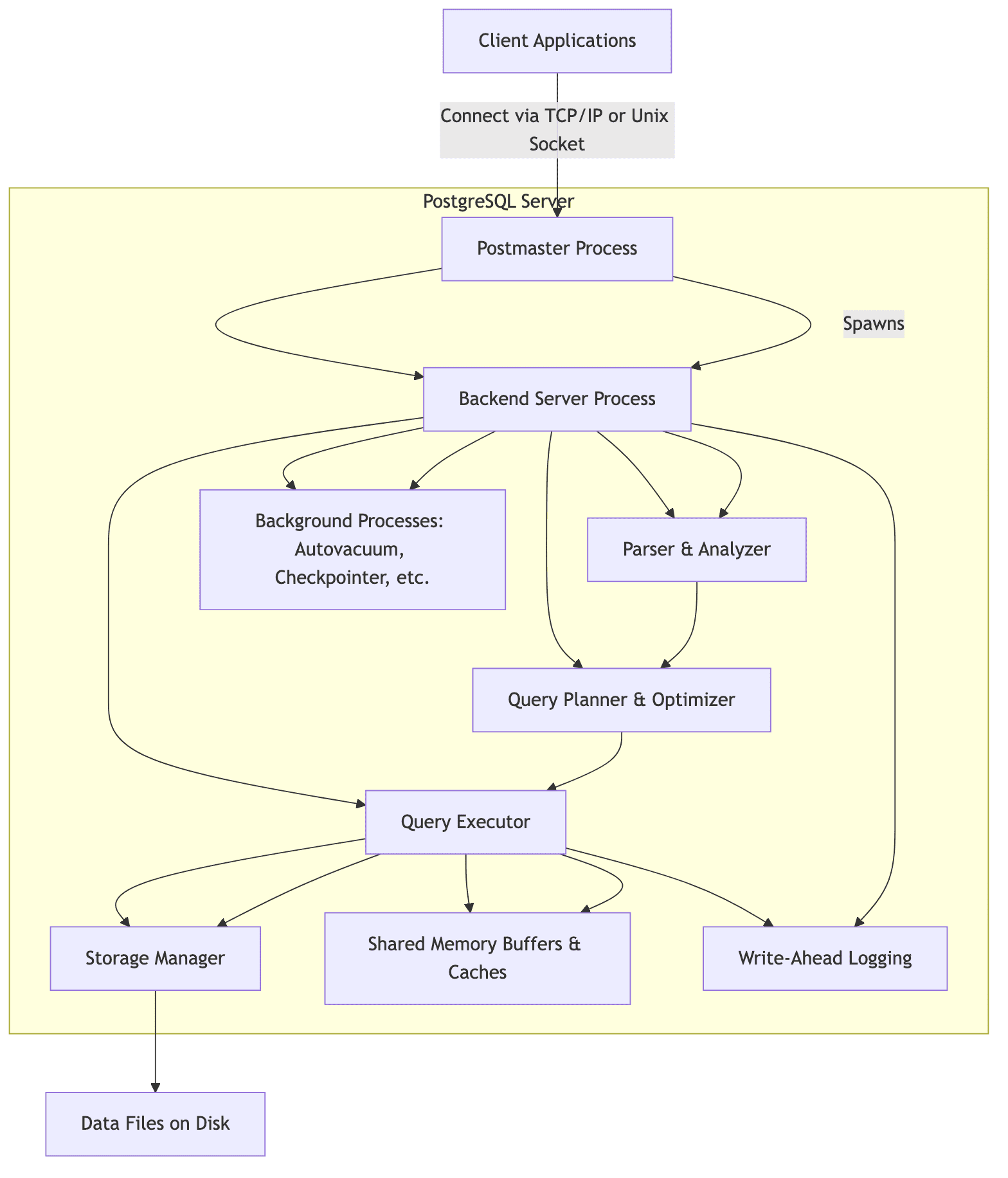
It provides a robust framework for managing concurrent queries, data durability and performance optimization. Being open-source, there a a lot of community created postgres extensions that enhance its capability even further.
Postgres usually runs on a single node and serve millions of IOPS depending on the server configuration. It is quite performance and cost-efficient. But at enormous scale, it creates bottlenecks around data durability and performance.
To this end, there are a lot of ways Postgres can be made distributed such that it addresses different challenges and use-cases.
Distributed Architectures
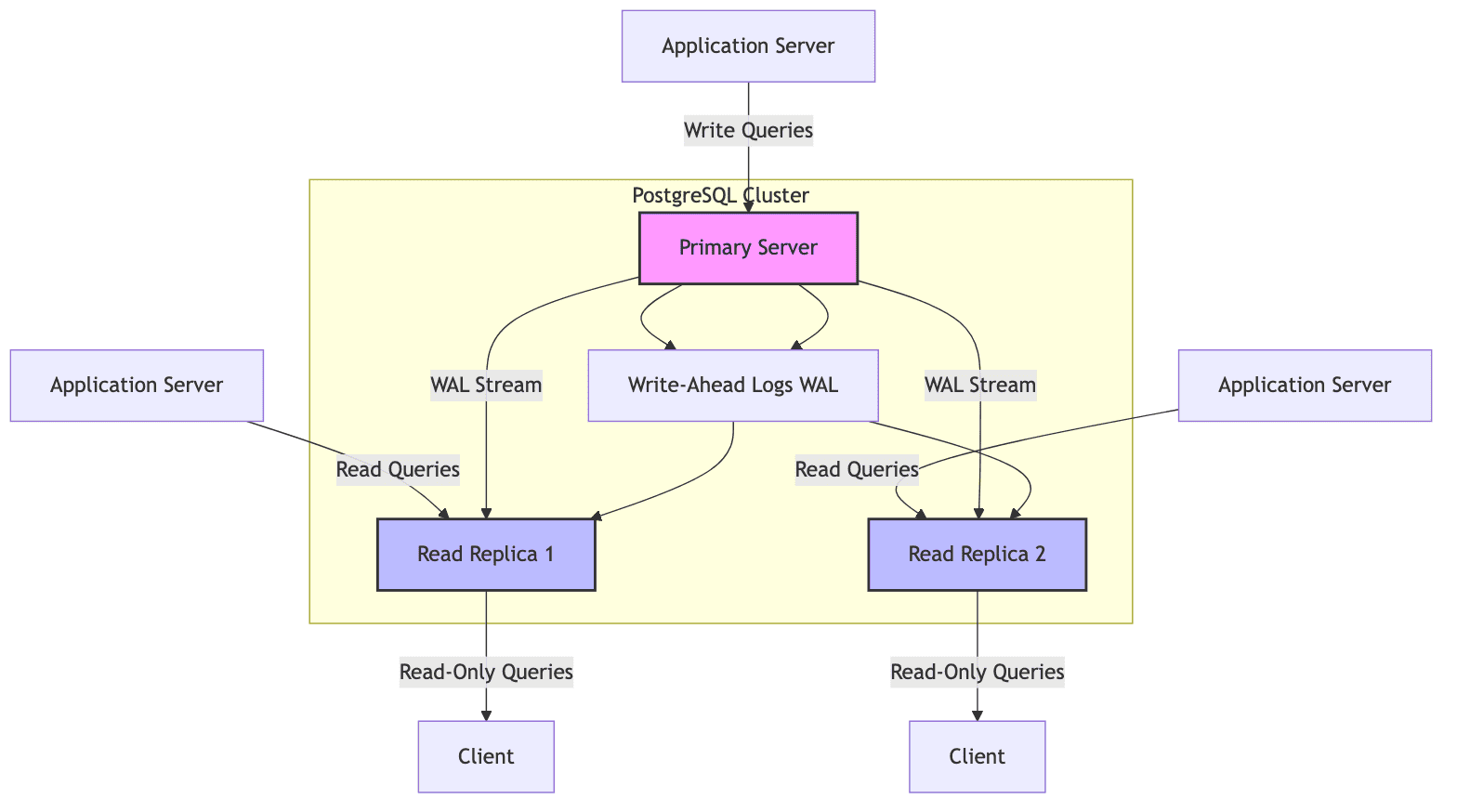
Master-Replica(Streaming) architecture
PostgreSQL comes with built-in support for replication to read-only replicas. This allows horizontal scaling of read workloads as the replicas handle the read queries while the primary server or master continues to manage write operations. This reduces load on the master.
This is done primarily through Streaming replication of the write ahead log (WAL) which ensures data consistency across the primary(master) and the replicas(followers).
The primary server or master:
- Handles all write operations (insert, update, delete)
- It can also handle read requests
- Generates Write-ahead logs(WAL) which records every change to the database before it is committed
- Sends this WAL data to the replicas(followers) through streaming replication
The read replicas:
- Operate in hot standby mode, and only accept read queries
- is promoted to a primary/master when the master fails
- Receive the WAL received from the master through streaming replication and apply them to converge at the same state as the primary/master
The replication can be asynchronous or synchronous. Synchronous replication waits for the replicas to confirm they have applied the WAL changes, trading increased latency with stronger consistency.
Active-active(multi-master) architecture
Active-active architecture allows concurrent write operations across multiple replicas or database nodes, creating a complex ecosystem of data synchronization(consistency) and conflict management.
It provides high availability, scalability and fault-tolerance by distributing writes and reads across multiple nodes. However, PostgreSQL doesn't natively support multi-master replication and therefore this is enabled using extensions like BDR (Bi-directional replication).
BDR (Bi-directional replicaiton)
It is a PG extension that enables asynchronous multi-master replication. It allows multiple nodes to replicate changes to each other creating a mesh. It applies changes on the peer nodes only after the local commit.
It uses logical replication for replicating data rows based on their replication identity(primary key). This is different than physical replication that transfers blocks/block addresses and byte replication.
There can be conflicts when multiple nodes apply changes to the same related rows. The BDR user application has to specify how to resolve this.
Conflict detection and resolution
BDR provides 3 levels of conflict detection:
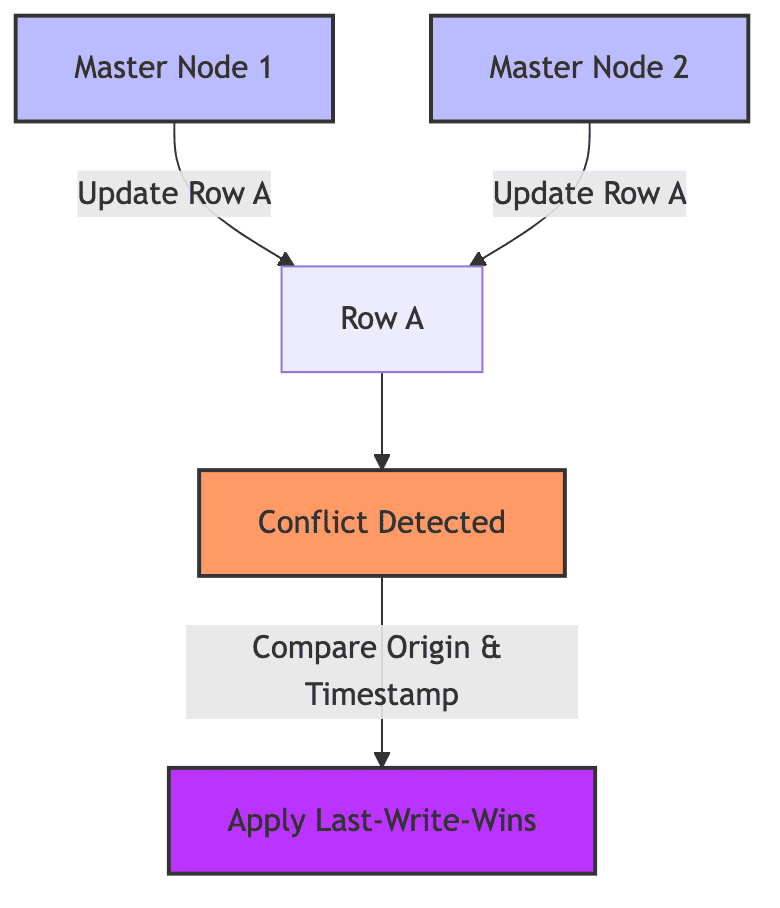
- Origin conflict detection:
Default method used in BDR. It identifies changes baed on the origin of the conflicting changes, where each
change is associated with a unique node id.
If two nodes attempt to modify the same row, BDR compares the node id and the associated timestamps of the conflicting transactions.
The resolution depends on what the application user has configured (ex. Last-write-wins(LWW)).
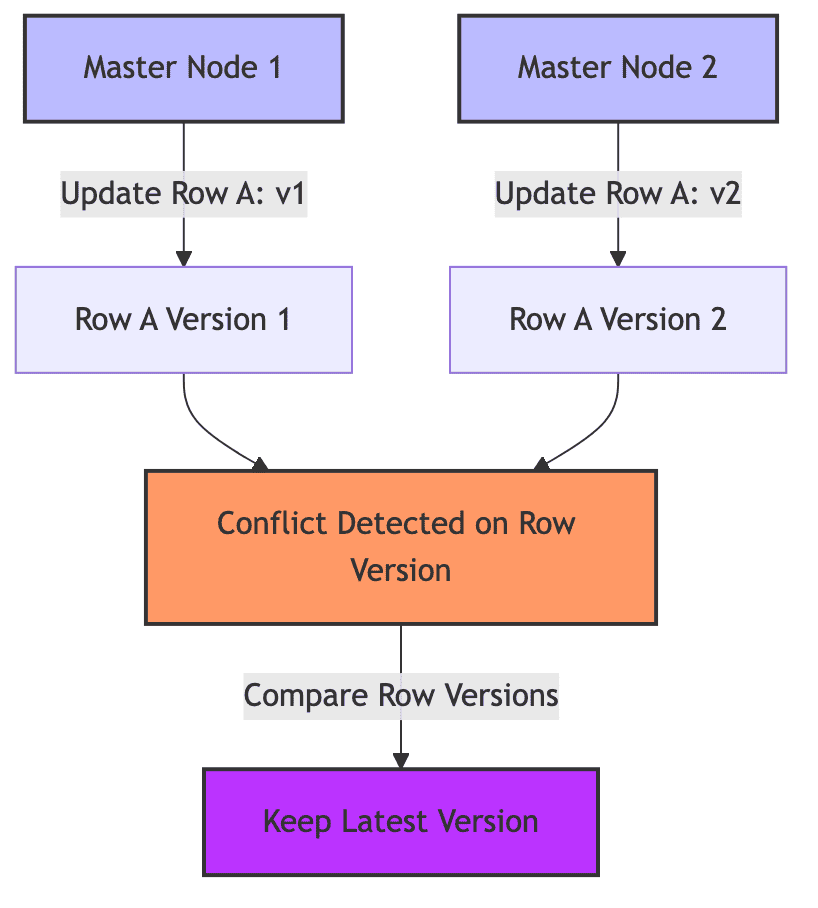
- Row version conflict detection
This detection strategy uses the row version numbers (or modification timestamps) to identify conflicts.
Each row in PG is assigned a version identifier (xminor modification timestamp). When changes to the same row are replicated
from multiple nodes, BDR compares their row versions and applies the conflict resolution strategy that has been selected.
It is more granular than origin-based conflict detection because it directly inspects the row version history.
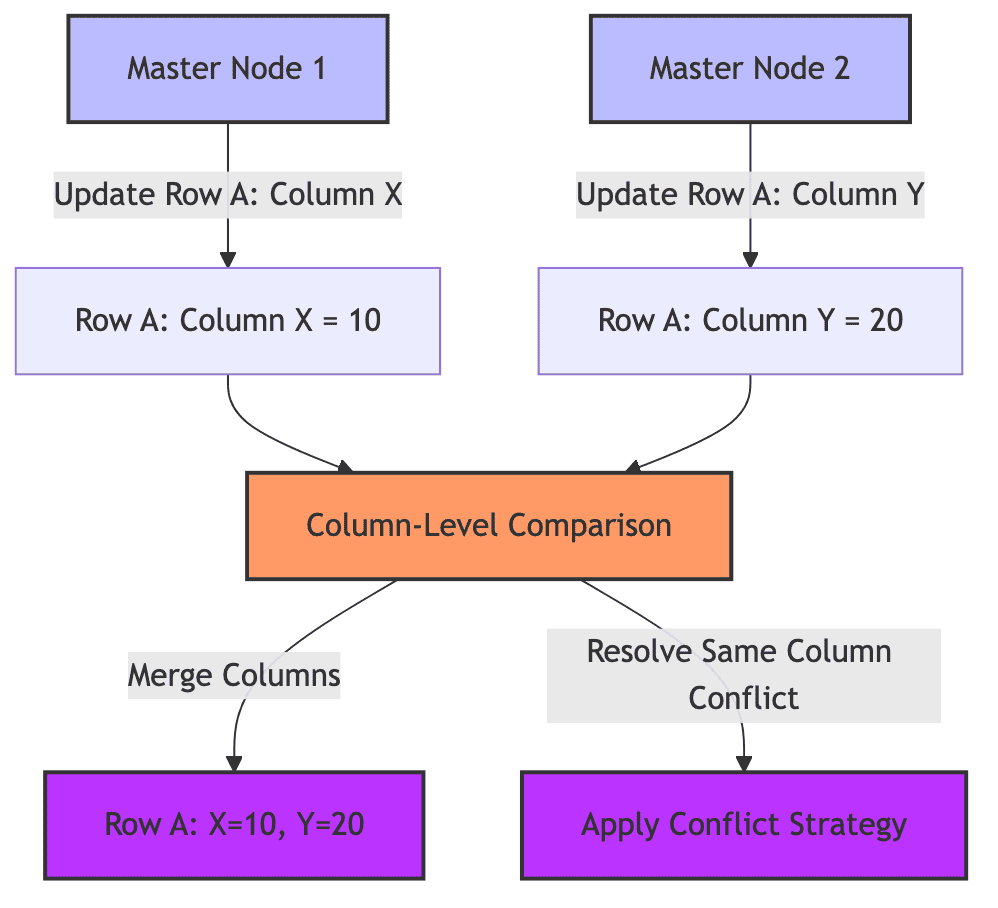
- Column level conflict detection
Instead of comparing entire rows, this strategy identifies conflicts at the column level. This allows changes
to the same row to be merged without conflicts.
Each column is individually compared when conflicts arise. If two nodes modify two different columns, then
the changes are merged. If the same column is modified, then a conflict resolution strategy such as LWW (last-write-wins) is used.
In summary:
| Mechanism | Granularity | Conflict Criteria | Best Use Case |
|---|---|---|---|
| Origin Conflict | Node-level | Compare origin node ID and timestamp | Simple setups with minimal conflicts |
| Row Version Conflict | Row-level | Compare row versions or modification times | Detecting row changes in detail |
| Column-Level Conflict | Column-level | Compare individual column changes | Highly granular conflict detection |
Conflict resolution using CRDTs
CRDTs (conflict-free replicated data types) are a type of data structures that PG can use to resolve conflicts that arise during multi-master writes. They are designed for distributed systems and can merge changes deterministically without conflicts.
CRDTs operate under the assumption that operations are commutative, associative and idempotent.
Examples of CRDTs offered by BDR:
- crdt_gcounter
- crdt_gsum
- crdt_pncounter
- crdt_pnsum
- crdt_delta_counter
- crdt_delta_sum
Distributed Transactions
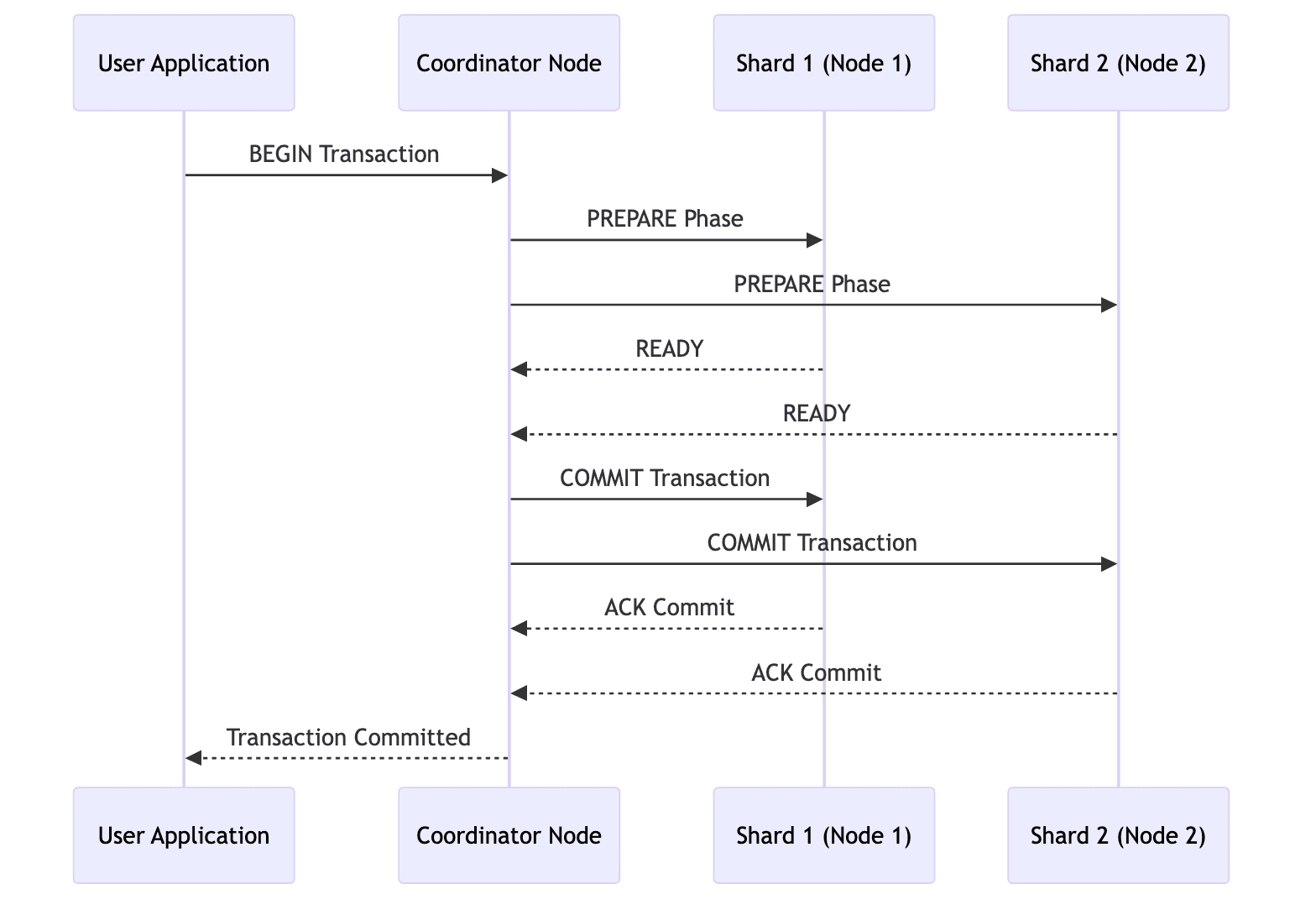
To ensure consistency across multiple nodes during transactions and to preserve the ACID properties of PostgreSQL, it uses 2PC (Two phase commit). It manages distributed transactions in two phases:
- Phase 1(Prepare): Nodes prepare to commit the transaction and confirm readiness
- Phase 2(Commit): Once all nodes confirm, the coordinator commits the transaction
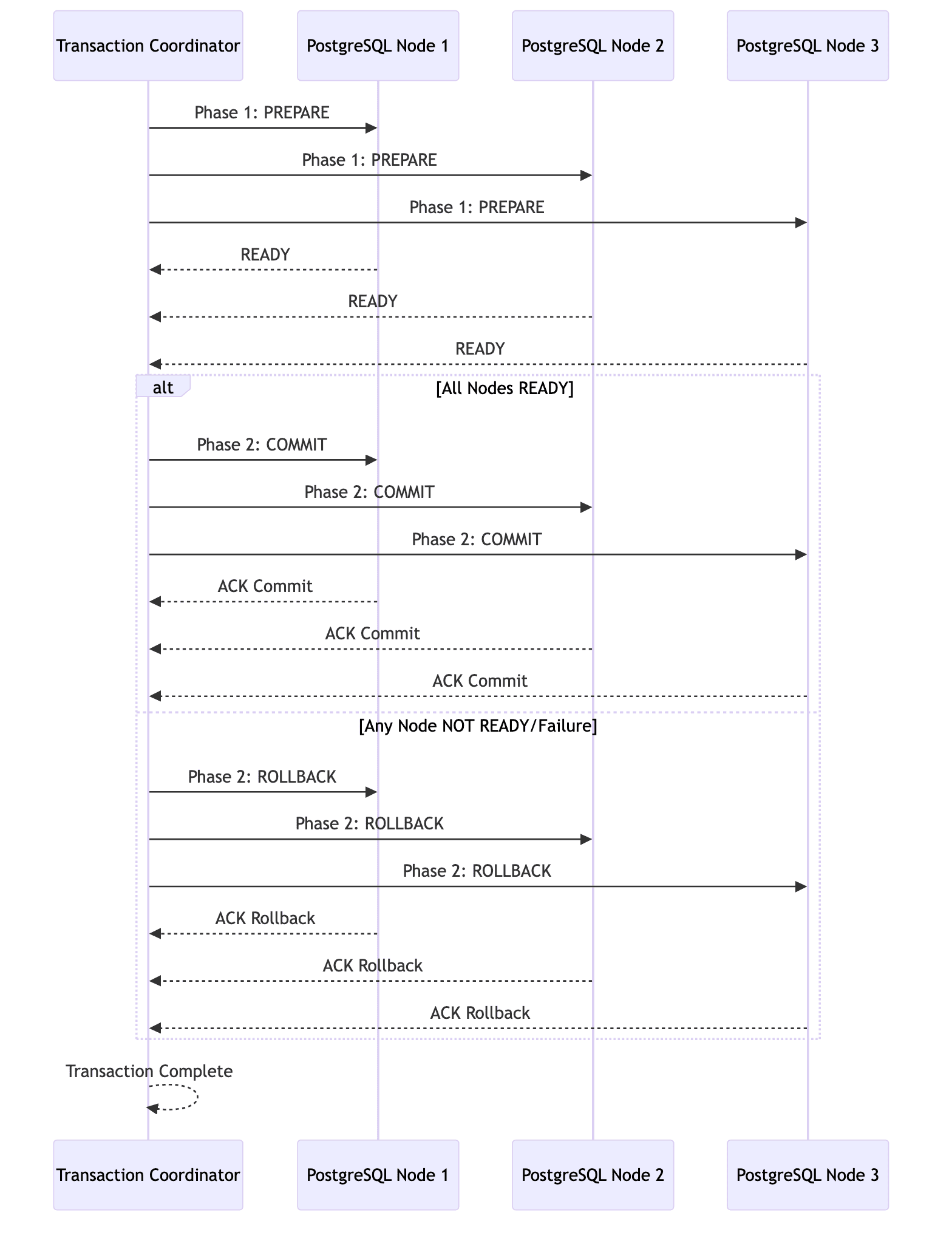
Sharded Architecture
PostgreSQL can also be scaled horizontally by sharding data and distributing it across multiple nodes. The Citus extension in PG can be used to transform PG into a distributed database that can efficiently handle large datasets and queries.
It provides:
- Distributed Tables
Large tables are sharded (split into smaller partitions) and distributed across multiple worker nodes. There are 2 types of distributed tables:- Reference Tables: Small tables replicated to all nodes for fast lookups
- Distributed Tables: Large tables that are sharded across multiple nodes using a hash or range-based distribution method
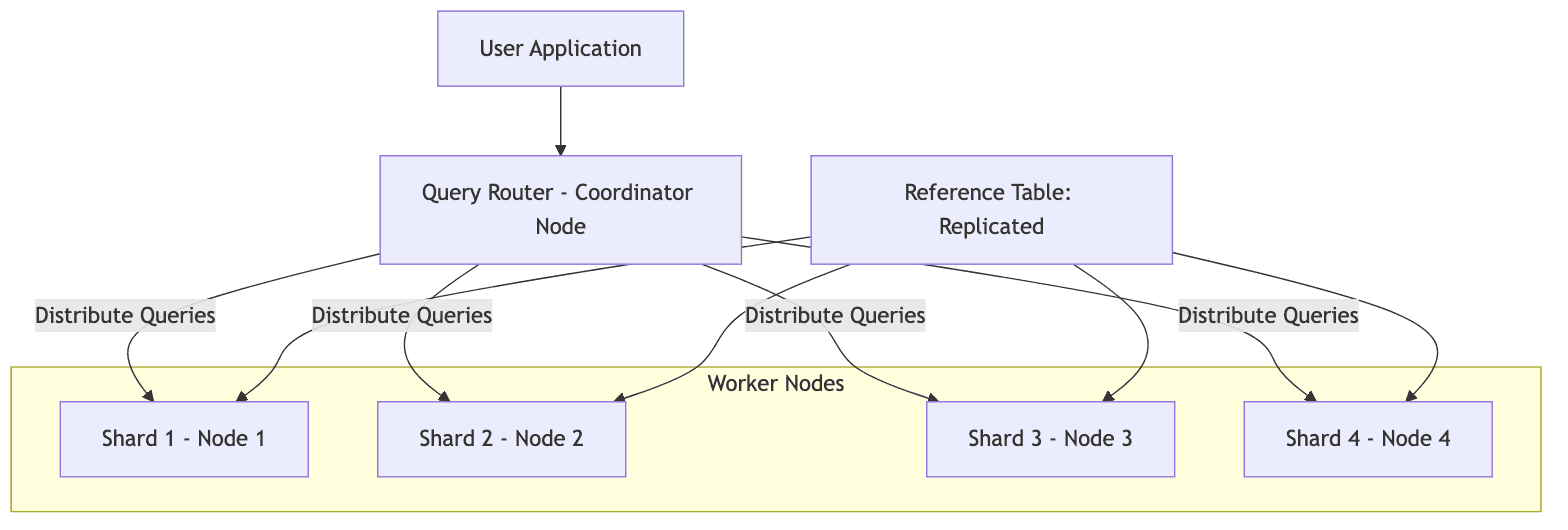
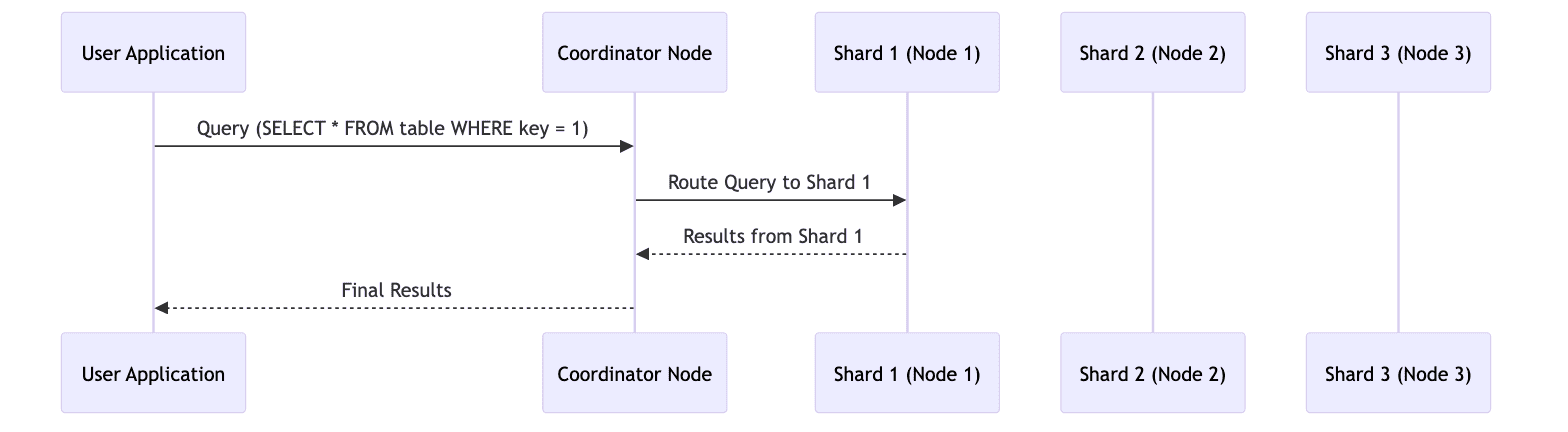
- Query Routing
Citus handles query routing by distributing queries using the shard key of the distributed table. This routes them to specific worker nodes holding the shard.
Queries involving a single shard are sent to a single worker whereas, queries spanning multiple shards are parallelized across all worker nodes holding those shards.
The coordinator node combines all the results from the workers and combines it before returning it to the client.
- Consistency and Transaction Management
Citus ensures ACID transactions across all shards.
- If a transaction involves only a single shard, it behaves like a single-node PostgreSQL transaction.
- For transactions spanning multiple nodes, Citus uses 2PC (Two-phase commit) protocol as demonstrated in the earlier section on distributed transactions.
- Consistency is guaranteed on each node using PostgreSQL's MVCC(Multi-version concurrency control).
Cloud-based Architectures
PostgreSQL is offered by leading cloud vendors as a managed service. For example, AWS offers RDS or Relational Database Service that provides managed PostgreSQL among many other open-source database management systems.
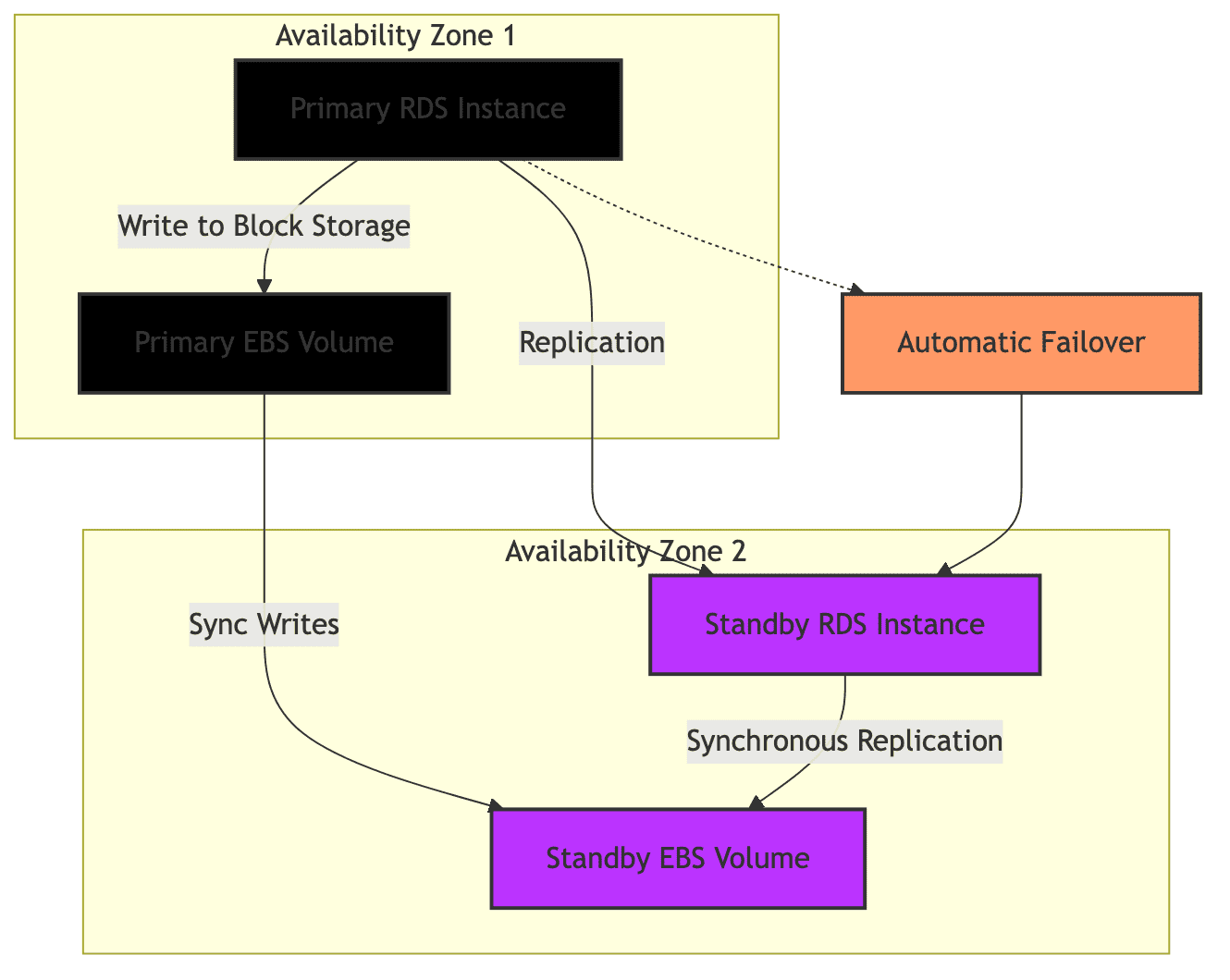
RDS with EBS (Network attached storage)
RDS uses Amazon EBS(Elastic Block Store) for storage. This uses a block storage API which can replicate blocks across different AZs(availability zones) to provide reliablity and high availability.
Some other examples of cloud based architectures include AWS Aurora Postgres that provides a distributed storage layer and scales automatically upto 128 TiB without downtime.
Conclusion
In conclusion, PostgreSQL can be scaled horizontally using different architectures to handle distributed data-intensive applications. From the traditional master-replica setup to more complex active-active and sharded architectures, PostgreSQL can be tailored to meet the needs of different use cases. Extensions like BDR and Citus further enhance its capabilities, enabling multi-master replication and horizontal scaling.
Choosing the right PostgreSQL architecture and scaling strategy is critical for long-term success. I help start-ups and scale-ups design and scale their database infrastructure to handle growing data volumes while maintaining performance. If you're also looking to strengthen your team, my hiring advisory services can help you recruit database engineers and architects who understand distributed systems.
Do leave a like if you liked this post and make sure to stay tuned for upcoming posts on distributed data intensive systems.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.