
2024-08-04
Understanding Replication in Distributed Data Systems. Part-1
This is a series of blog posts about distributed data-intensive systems.
Distributed Data-Intensive Systems. Understanding Replication. Part-1
This is a series of blog posts about distributed data-intensive systems, what they are, how they're designed and the problems, trade-offs and optimizations in their context.
An excellent read on a more general overview of distributed systems and data-intensive applications can be found in the book by Martin Kleppmann.
Here is the entire series so far:
- Understanding Replication. Part-1 (You're here)
- Understanding Replication. Part-2
- Distributed Postgres Architectures
- Leaderless Replication: Quorums, Hinted Handoff and Read Repair
Contents
- What is Replication?
- Single Leader Replication
- Synchronous and Asynchronous Replication
- Up-to-date Replicas
- Handling Node Outages
- Implementation of Replication Logs
- Conclusion
What is Replication?
Replication means copying information/data from one machine to the other, such that they're both in a consistent up-to-date state. In the context of distributed data systems, it means keeping a copy of that data on multiple machines. These machines are generally connected over a network.
It is useful in many scenarios:
- Fault tolerance: If the state of the system is replicated across multiple machines, it is not lost if the primary machine goes down or is unavailable.
- Balancing Load: With multiple replicas of the data on multiple machines, the incoming queries can be balanced across different replicas.
- Reduce access latency: Replicating data/state across geographically distributed machines, reduces access latency for consumers close to those replicas.
There are 3 main ways to handle replication in a distributed data system:
- Single Leader replication
- Multi leader replication
- Leaderless replication
Single Leader Replication
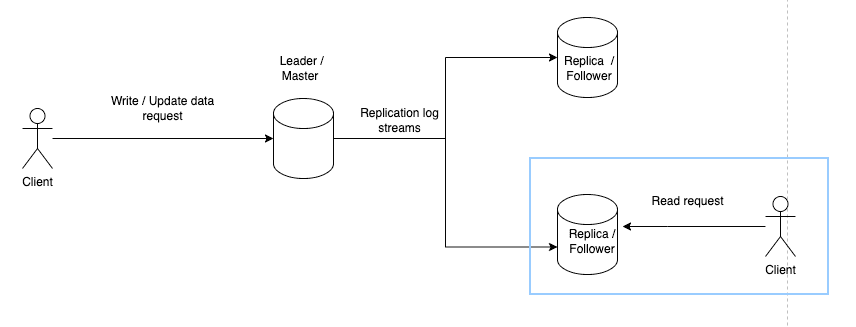
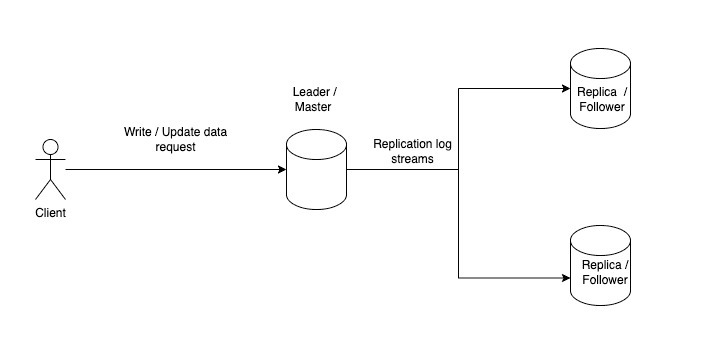
In this type of replication, we have a single leader or master, and multiple followers or replicas. The master is the primary node with the most up-to-date state/data.
It is also called active-passive or master-slave, master-follower replication. All operations on the master are replicated to the followers or replicas to keep them in sync.
-
Whenever a client wants to write or mutate data in such a system, it must send its request to the leader/master. The leader then writes the data to its local storage before replicating it to the other follower replicas.
-
The followers consume from the replication log streams of the leader and apply changes to their own replica.
- Whenever a client wants to read from the system, the query can be processed by any replica as it maintains an up-to-date copy of the state of the system.
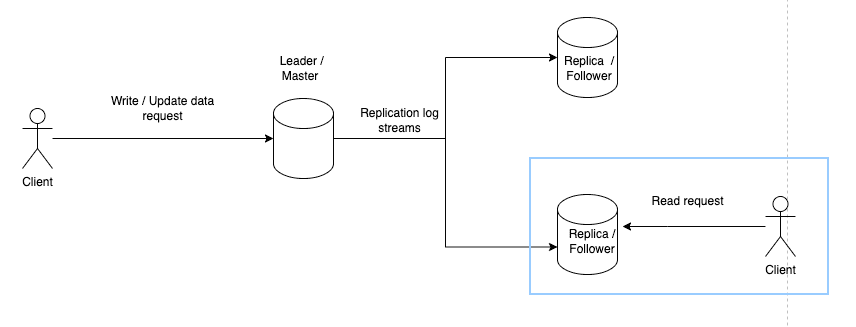
This type of replication is supported in multiple databases like PostgresSQL, MySQL and SQL Server.
Distributed message brokers such as Kafka and RabbitMQ also use leader-based replication.
Synchronous and Asynchronous Replication
There are two main ways a system replicates its state to its followers. One is synchronous and the leader waits for the follower to acknowledge that the state has been committed before returning back to a client. Another is asynchronous, where the leader commits and returns a response back to the client. It replicates the state to the follower but doesn't wait for the follower to acknowledge it.
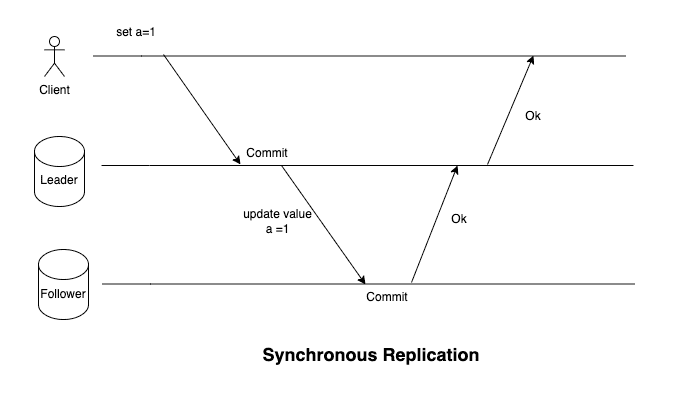
Synchronous replication ensures that data is successfully replicated but it does so at the cost of latency. There can be scenarios where the follower is down or the network is congested, which might lead to delay in committing and acknowledging the update from the leader. All this while, the client is waiting on a response from the system.
Asynchronous replication on the other hand, optimizes for latency. The leader commits the data and responds back to the client. It also sends the update to the follower simulataneously but does not wait for the follower to acknowledge the update.
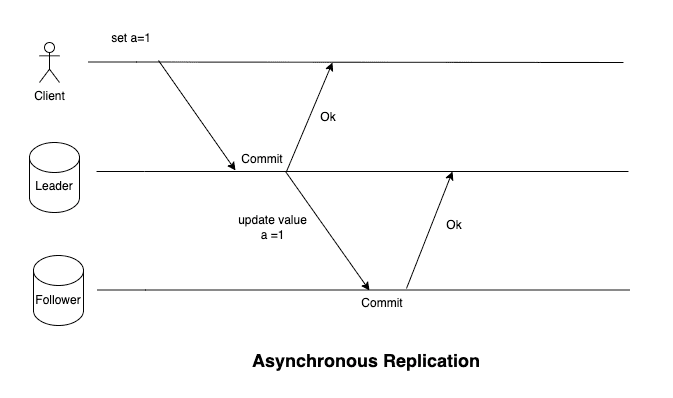
In the case of synchronous replication, the leader must block all writes until the follower has acknowledged the update. Therefore, it is not quite practical for majority of the use-cases.
In practice, most systems have a single synchronous follower and the others are all asynchronous followers. The leader waits for acknowledgement from a single follower before responding to the client. It also replicates these changes to the other followers asynchronously. This kind of setup is usually called semi-synchronous.
Up-to-date Replicas
Replicas might need to be added to a system in order to scale it or to make the system more durable. A common problem is getting the replica up to the date with the current state of the system.
Simply copying the files from the leader node might not be feasible as:
- The system would be receiving writes continously so the state of the system would diverge from the time when the files were copied and applied in the new replica
- This would also put the leader under load as it has to respond to the requests while making a copy of its current state.
The following steps can be taken to get a replica up and running:
- Take a snapshot of the data from the leader node. This records the current state of the system up to a certain point in time.
- Copy the snapshot onto the replica and persist it to disk.
- When the replica comes back up, it compares its state with that of the leader. This can be done by associating the snapshot with a deterministic checkpoint on the leader's replication log, for example: a monotonically increasing sequence number. The replica can then compare its sequence number with that of the leader's most recent sequence number and request all the changes to start applying them to its own log.
- After this backlog has been processed and the follower has caught up with the leader, it can then start processing changes from the leader as they happen.
Handling Node Outages
Node outages are a very common in a distributed system and it must be able to recover from node outages without any downtime.
As a system has two types of nodes: leaders and followers, any of them can go down. To be highly available, there are some things we can do to ensure that the system as a whole continues to function:
Follower Failure
A follower node keeps a track of all the changes that it has received from the leader on its local disk. In the event of node or network failure, once the follower comes back up, it can request changes from the leader from the time that it had been disconnected from the system. Once it catches up to the leader's replication log, it can then start receiving changes as they happen.
Leader Failure
If a leader node fails, one approach is to have another replica as a standy that can be promoted to a leader. This is called a failover.
As an example, Postgres has the concept of a hot standby that can be used as a failover in case the leader node goes down.
Automatic failover mechanisms look something like this:
-
Determining if the leader has indeed failed. The most common way of doing this is via timeouts/heartbeats. As a leader node can go down or get network partitioned from the followers, most systems implement a heartbeat mechanism as a way of confirming that a node is up. If a heartbeat ping is not received for a specified time, say 30 seconds, the node is considered down. In case of a leader, this triggers leader election in a distributed data system.
-
Leader election. Once a leader node is declared down, the followers go through the process of leader election. This can be done via a controller node (for example: using Zookeeper for earlier versions of Apache Kafka). The best candidate for leader promotion is recognized, this is usually the follower with the most up-to-date state. The next step is for all the nodes to agree on a leader and start accepting changes from this new leader. The process of agreeing on a new leader is part of the Consensus problem in distributed data systems.
There are some disadvantages of leader failover:
-
When the old leader comes back up, it might have some writes in its log that were not propagated to the followers before it went down. The most common way is to discard these writes but that might impact the durability guarantees of the system. In some cases, these stale unpropagated logs can be compared with the current state of the system or be resolved at the application level.
-
The old leader that comes back up, might still believe that it is the leader. This can lead to two different nodes believing they are the leaders. This is called a split brain. One way of resolving this can be for the old leader to send status requests to the nearest follower nodes and check the latest sequence numbers in their replication logs. If these are greater than those of the leader, then the leader is lagging and will reach out to the new leader to catch up.
-
The timeout of the leader heartbeat should be chosen carefully. A long timeout would result in the system being unavailable during that time and a shorter timeout would lead to unnecessary leader elections that would put more load on the system.
Implementation of Replication Logs
There are various ways replication logs can be implemented in distrbuted data systems:
Statement Based Replication
In this type of replication, the leader writes all statements that it executes onto a log and sends these statements to its followers to be replicated. The follower then parses this log and executes the statements locally to update its state to that of the leader.
The major downside of this type of replication is:
-
Non-deterministic functions can cause different results on the leader and the follower. For example: if a statement is executed with the
RAND()function, it can yield different random numbers in the leader and the follower. -
Auto-incrementing columns or statements mutating existing data, must be executed in the same order that they're received in. This is hard to achieve with multiple concurrently executing transactions.
Write-ahead-log (WAL) Shipping
Many distributed data systems, implement a write ahead log where any change to the system is logged to this append-only sequence of bytes before being written.
The leader then sends or streams this log to the followers across the network.
Some examples of systems that implement this are PostgreSQL and Oracle.
It is a robust way to replicate state but suffers from strong coupling to the underlying storage engine implementation. If the implementation of the storage format changes from one version to the other, it is quite difficult to upgrade all the nodes without downtime.
Logical Row-based Log Replication
The replication can also be decoupled from the storage engine. This is called a logical log which is different from the physical data representation.
A logical log records changes to the system at the level of a row or tuple. In the case of distributed databases, each row changed in a table of a database/schema would be recorded.
Change data capture software like Debezium work like this.
- For each insert, the log contains the new values of columns along with the relevant metadata
- For a delete, the logs records the primary key and other relevant metadata to identify the record to be deleted
- For an update, it records the primary key and metadata to identify the row/record to update and the new values
Trigger-based Replication
A trigger in distributed databases, is a piece of application code that can be executed as soon as data changes and certain conditions are met. It is closely coupled to the distributed system that is being replicated.
An example could be a trigger in a Postgres database that logs the changes into a history table for auditing as soon as a change occurs in the main table being replicated.
Conclusion
Replication is a basic requirement for creating a distributed data system. It not only provides scalability but also fault tolerance. Synchronous and asynchronous replication are the main ways leaders replicate data/state to their followers. Replication logs in leaders are implemented via different mechanisms, with logical row based log replication being the most widely used since it decouples the log from the underlying storage engine implementation.
Understanding replication patterns is essential when building distributed systems at scale. I work with companies to architect and scale their distributed data infrastructure, ensuring they choose the right replication strategies for their use cases. If you're building a team to support these systems, my hiring advisory services can help you find engineers with deep expertise in distributed systems and data replication.
Do leave a like if you liked this post and make sure to stay tuned for upcoming posts on distributed data intensive systems.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.