
2025-09-02
Leaderless Replication: Quorums, Hinted Handoff and Read Repair
Two approaches have emerged to tackle the replication challenge: leader-based replication and leaderless replication. This article delves into the latter, exploring quorums, gossip protocols, sloppy quorums and hinted handoff.

Leaderless Replication: Quorums, Hinted Handoff and Read Repair
In the world of distributed data systems, ensuring data consistency, availability and durability is a foundational challenge. As applications scale, the strategy for replicating data becomes a critical design decision. Two approaches have emerged to tackle the replication challenge: leader-based replication and leaderless replication. This article delves into the latter, exploring quorums, gossip protocols, sloppy quorums and hinted handoff.
While data engineers may not directly implement these replication strategies in their daily work, understanding the fundamentals of leaderless replication, quorums, and distributed consensus significantly enhances the ability to make informed architectural decisions, troubleshoot performance issues, and optimize data pipelines when working with distributed systems like Cassandra, DynamoDB, or other NoSQL databases.
Here is the entire series so far:
- Understanding Replication. Part-1
- Understanding Replication. Part-2
- Distributed Postgres Architectures
- Leaderless Replication: Quorums, Hinted Handoff and Read Repair (You're here)
Contents
- Introduction
- Leaderless Architecture and the CAP theorem
- Quorums for Tunable Consistency
- Handling Failure and Ensuring Convergence
- Leaderless Replication in Practice
- Conclusion
Introduction
Data replication involves maintaining multiple copies of data on different machines/nodes to achieve fault tolerance and high availability. If one server fails, another can take over. The primary challenge lies in coordinating updates across these replicas to ensure consistency.
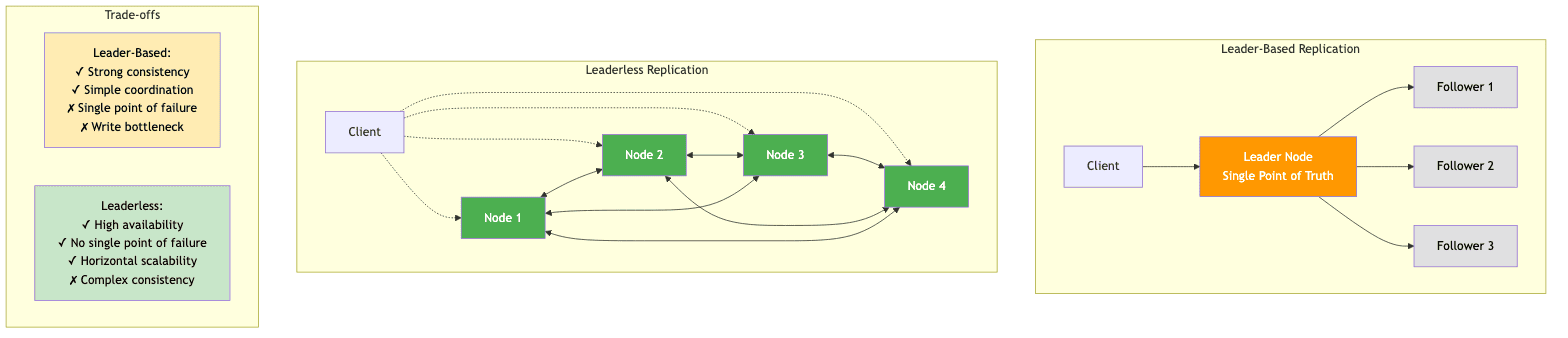
Leader-Based(Master-Slave) Replication
The most common approach is leader-based replication. In this model, one replica is designated as the leader(or master), while the others are followers(or slaves). All write operations from clients are sent to the leader, which processes the write, updates its local storage and then propagates the changes to the replicas/followers.
This approach simplifies consistency management since the leader is the single source of truth. Databases like MySQL, PostgreSQL and SQL Server rely on this model. However, this model has its drawbacks:
- The leader represents a single point of failure. If the leader goes down, a new leader must be elected, which can lead to downtime.
- The leader can become a bottleneck under high write loads, limiting scalability.
- Network partitions can lead to split-brain scenarios, where multiple nodes believe they are the leader, causing data inconsistencies.
- In some asynchronous configurations, it may lead to data loss if the new leader has not received all the latest writes from the old leader.
Leaderless(Dynamo-style) Replication
Leaderless replication, popularized by Amazon's Dynamo paper, takes a completely decentralized, peer-to-peer approach. In this architecture, there is no designated leader. Any node can accept read or write requests from clients. This model inherently prioritizes high availability and fault tolerance. Since there is no single point of failure, the system can continue to operate even if some nodes are down, as long as sufficient replicas are available to satisfy the configured quorum requirements.
Apache Cassandra, the original Amazon Dynamo and Riak KV are examples of systems built on leaderless replication.
The choice between leader-based and leaderless replication depends on the requirements of the application. Leader-based systems are chosen for applications where strong consistency is paramount, such as financial systems, accepting potential downtime as a trade-off for consistency. Leaderless systems are ideal for applications like social media platforms and IoT services, where constant uptime and data ingestion are more important and the system can tolerate a brief delay before users see the latest data(eventual consistency).
Leaderless Architecture and the CAP theorem
Let's understand the CAP theorem which is an important concept in distributed systems theory.
CAP Theorem
The CAP theorem, also called Brewer's theorem, states that in a distributed data store, it is impossible to simultaneously provide all three of the following guarantees:
- Consistency (C): Every read operation receives the most recent write or an error. i.e. In a consistent system, all nodes see the same data at the same time, irrespective of which node they connect to.
- Availability (A): Every request receives a non-error response, without the guarantee that it contains the most recent write. The system remains operational for both reads and writes even if some nodes are down.
- Partition Tolerance (P): The system continues to operate despite network partitions i.e. some nodes cannot communicate with others due to network failures. A partition means that messages between nodes may be dropped or delayed.
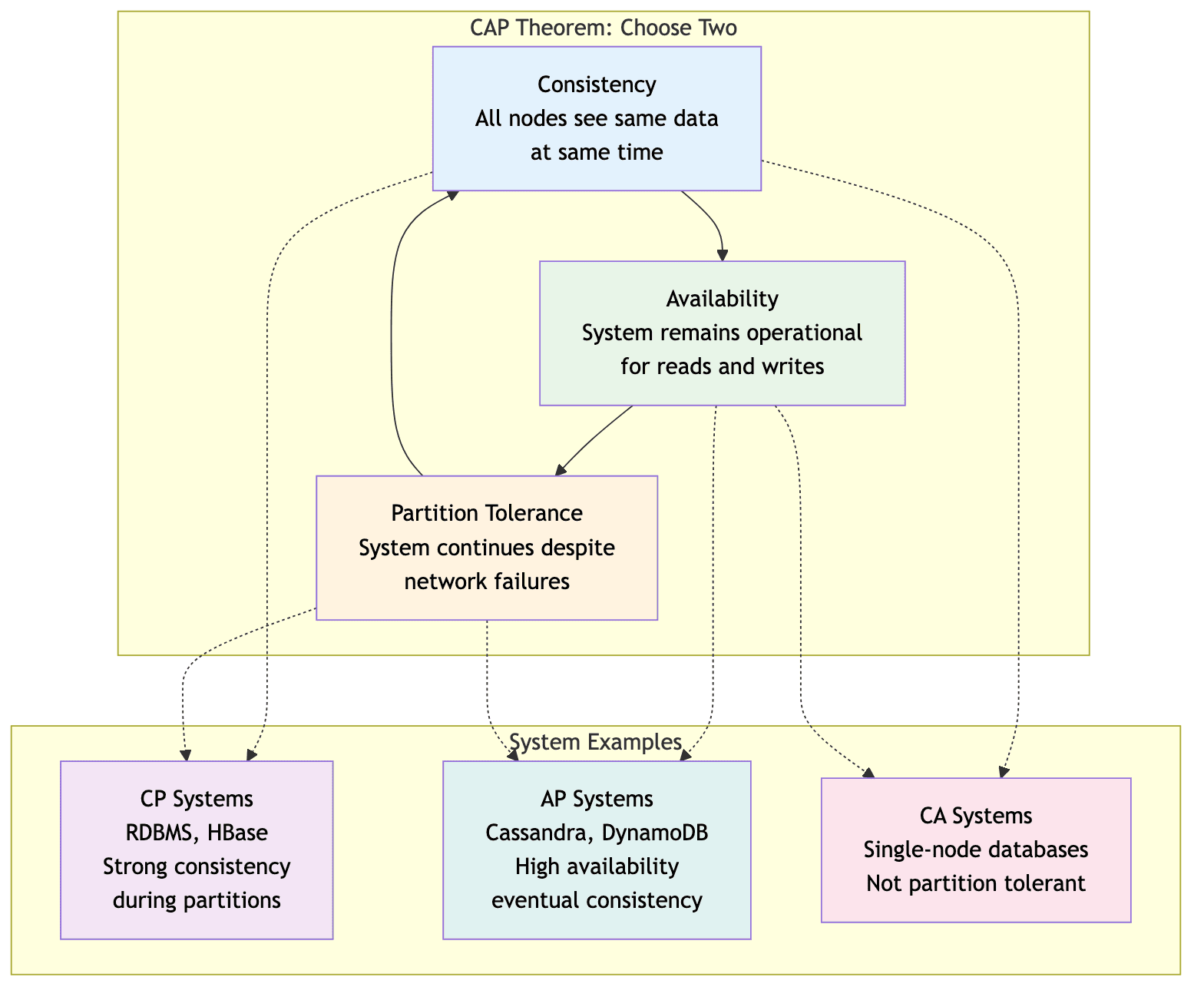
In any real-world distributed system, network partitions are inevitable. Therefore, a distributed data system must be partition-tolerant. This means that when a network partition occurs, the system must choose between consistency and availability.
The system can either be: CP (Consistent and Partition-tolerant) or AP (Available and Partition-tolerant).
Leaderless systems as AP
Leaderless databases like Cassandra are fundamentally designed as AP systems. They are architected to prioritize availability and partition tolerance above all else. When a network partition occurs, a leaderless system will choose to remain available and allow clients to continue reading and writing to the nodes they can reach. This comes at the cost of immediate consistency, as different nodes may have different versions of the data until they can synchronize. A write made to one side of the partition may not be visible to the client reading from the other side of the partition until the partition is resolved and the nodes can communicate again. This model is described as providing eventual consistency, where the system guarantees that, given enough time without new updates, all replicas will converge to the same state.
This however, can be misleading. The term eventual consistency suggests that the system is often in a weak or unreliable state. A more accurate description for systems like Cassandra is tunable consistency. These systems do not abandon consistency altogether, instead, they transform it into a configurable parameter that can be adjusted based on the application's needs. For example, an application can perform a non-critical operation like logging a "like" on a social media post with a low consistency level for maximum speed and availability. For a critical operation like updating a user's password, the application can demand a higher consistency level to ensure the write is durably persisted and immediately visible to subsequent reads.
Quorums for Tunable Consistency
The mechanism that allows for leaderless systems to provide tunable consistency is the concept of quorums. It is a voting based approach to ensure operations are validated by a minimum subset of nodes before being considered successful.
W + R > N Formula
Quorum consensus provides a mathematical guarantee of consistency through a simple formula:
W + R > N
- N (Replication Factor): The total number of nodes that store a copy(replica) of the given piece of data.
- W (Write Quorum): The minimum number of nodes that must acknowledge a write before it is considered successful.
- R (Read Quorum): The minimum number of nodes that must respond to a read request to return a result.
The main ingredient of this formula is the overlap guarantee. By ensuring the the sum of the read and write quorums is greater than the total number of replicas, the system guarantees that the set of nodes participating in a read operation (R) will always intersect with the set of nodes that acknowledged the most recent write operation (W). This intersection ensures that at least one node in the read quorum has the latest data, thus providing consistency.
For example, consider a system with N = 3 replicas. A balanced configuration would be W = 2 and R = 2. Here, W + R = 4, which is greater than N = 3.
- When a client writes a value, the coordinator waits for at least 2 of the 3 replicas to acknowledge the write before confirming success to the client.
- When a client reads theat value, the coordinator requests data from at least 2 of the 3 replicas. Because there are only 3 replicas in total, any set of two replicas is guaranteed to overlap with the two replicas that acknowledged the write, ensuring that the read will return the most recent value.
Quorums and Performance Trade-offs
The flexibility of the quorum formula allows systems to tune their behavior based on the application's needs:
- Optimized for Reads(Slow Write, Fast Read): If we set
W = NandR = 1, every write must be acknowledged by all the replicas, making it slower but ensuring strong consistency. Reads become fast and highly available since only one replica needs to respond as it is guaranteed to have the latest data. - Optimized for Writes(Slow Read, Fast Write): If we set
W = 1andR = N, writes become fast as only one replica needs to acknowledge the write operation. However, reads become slower and resource-intensive since they must contact all replicas to ensure they get the most recent data. - Balanced Approach: A common configuration is to set both
WandRto a majority quorum calculated as(N/2) + 1. ForN = 3, this meansW = 2andR = 2. ForN = 5, this meansW = 3andR = 3. This balanced approach provides a good compromise between read and write performance while still ensuring strong consistency.
Handling Failure and Ensuring Convergence
Leaderless systems use a combination of techniques to handle node failures, detect inconsistencies and guide the cluster back toward a consistent state. These components work together to deliver high availability and eventual consistency.
Gossip Protocol
The gossip protocol is central to decentralized (pun intended) coordination in leaderless systems. It is a peer-to-peer communication mechanism where nodes periodically exchange state information with a few randomly selected peers. This might include node liveness, load information and schema versions that spread throughout the cluster epidemically. This ensures that all nodes eventually learn about the state of the entire cluster, even in the presence of network partitions or node failures.
Rather than relying on simple heartbeats which might be prone to false positives during network issues, systems like Cassandra use a more advanced algorithm called the Phi Accrual Failure Detector. Instead of making a binary up or down decision on the status of a node, it calculates a suspicion level(phi value) based on the history of heartbeat intervals. If the phi value exceeds a certain threshold, the node is considered down. This allows a more nuanced approach to failure detection, reducing the chances of false positives.
Phi Accrual Failure Detector
The Phi accrual failure detector works by continuously monitoring heartbeat messages and calculating a suspicion level (Phi value) based on the probability that a node has failed. At a high level:
- It maintains a sliding window of inter-arrival times between consecutive heartbeats to build a statistical model of normal behavior.
- Uses the mean and standard deviation of these inter-arrival times to model the expected hearbeat arrival pattern as a normal distribution.
- When a heartbeat is late/missed, it calculates the Phi value using the formula:
Phi = -log10(P_later)
whereP_lateris the probability that the next heartbeat will arrive later than the current time, based on the statistical model. - The Phi value is compared against a predefined configurable threshold. Higher Phi values indicate a higher suspicion of node failure.
It is particularly effective in environments with variable network latency, as it learns from historical patterns rather than using fixed timeouts.
Sloppy Quorums and Hinted Handoff
When a node goes down, a leaderless system needs to handle incoming writes for the data that resides on that node. Hinted Handoff and Sloppy Quorums are two related techniques that help maintain availability and durability during such failures.
Hinted Handoff
When a coordinator node attempts a write but finds that the target node is down(detected via the Gossip Protocol), it doesn't fail the write operation. Instead, it writes the data to another available node/replica (or store it locally) along with a hint. A hint is metadata indicating that this write is intended for the unavailable node. Once the failed node rejoins the cluster, the node holding the hint will hand off the write, sending the data to the originally intended node to ensure it eventually receives all updates.
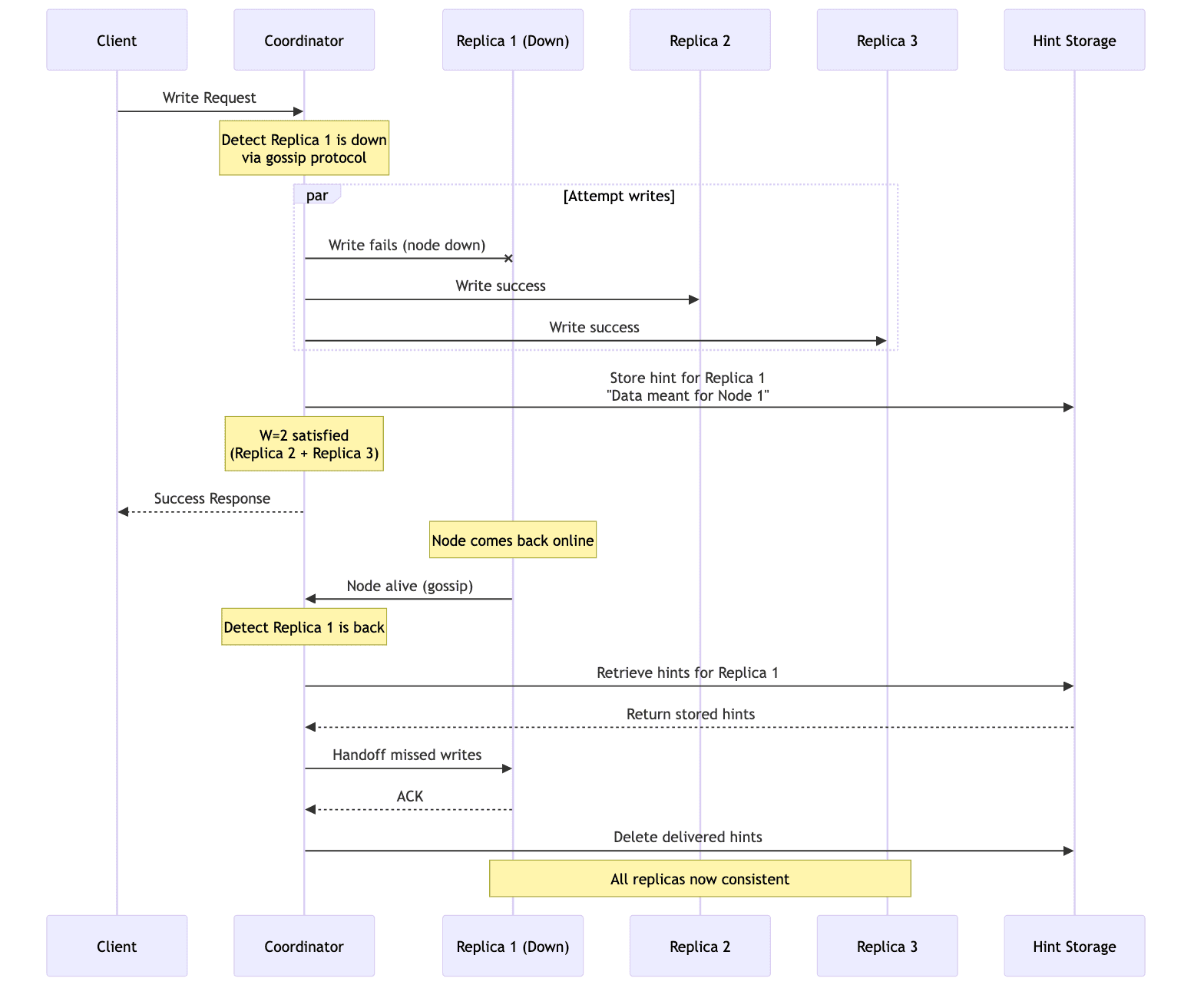
Sloppy Quorums
A Sloppy Quorum takes the handoff concept a bit further to ensure that the write operation succeeds from the perspective of the client sending the request. In a true sloppy quorum system, specifically the one described in the original Amazon Dynamo paper, if a write cannot reach enough of its primary replicas to satisfy the write quorum (W), the coordinator node can temporarily send the write to other healthy nodes that are not part of the primary replica set. This counts towards satisfying the write quorum, allowing the write to succeed even when some replicas are down. The system will later ensure that these writes are propagated to the correct replicas when they come back online.
While inspired by Dynamo, Apache Cassandra does not implement a true sloppy quorum. Cassandra uses hinted handoff, but a hinted write does not count towards satisfying the intended consistency level. For example, if the client requests a write with QUORUM consistency and one of the replicas is down, the write will fail and Cassandra will throw an UnavailableException. The hint is only stored for the downed replica if the write succeeds by meeting its consistency level with other remaining replicas. Cassandra prioritizes consistency guarantees over availability in this regard.
Repair Mechanisms
A node or replica that has been down may have missed writes that occurred during its downtime. To ensure that all replicas eventually converge to the same state, leaderless systems employ two primary repair mechanisms: read repair and anti-entropy repair.
Read Repair
This is an online, self-healing process that occurs during a normal read operation. When a client issues a read request with consistency level greater than ONE (ex. QUORUM), the coordinator node fetches data for digests(hashes) from multiple replicas. If it detects stale data in any of the replicas, it sends the most recent version to the outdated replica before returning the result to the client. This mechanism actively repairs inconsistencies as they are discovered during reads.
However, read repair only occurs for keys/data that are actively being read. If a piece of data is rarely accessed, it may remain inconsistent across replicas for a long time.
Anti-Entropy Repair
This is typically a background process that operates independently of client requests. It periodically compares all data between replicas and resolves any differences it finds. It is more thorough than read repair as it updates/repairs infrequently accessed data as well. Anti-entropy repair can be scheduled to run during off-peak hours to minimize its impact on normal operations.
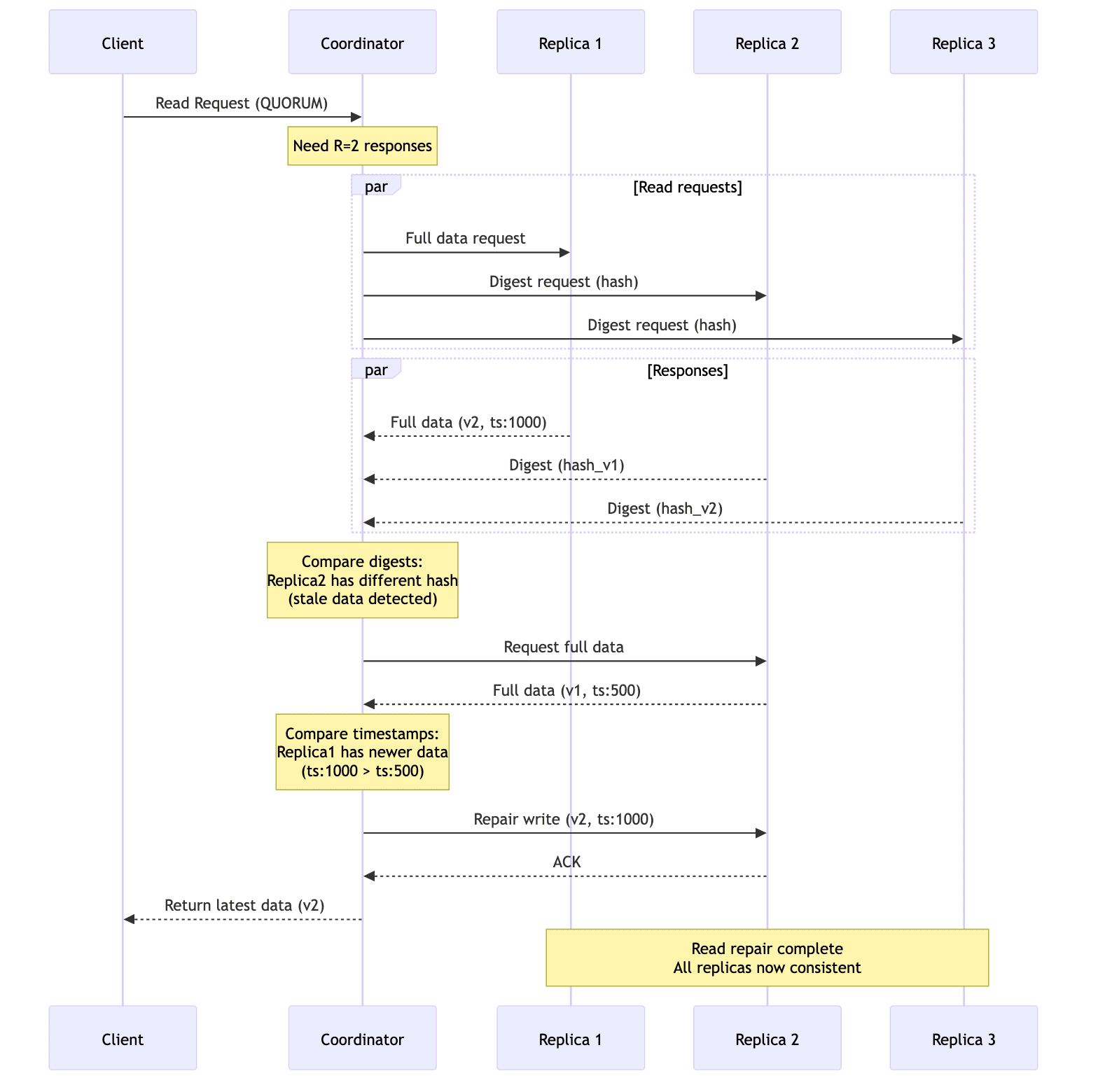
Read repair in Cassandra
- A client issues a read request at a consistency level (eg.
QUORUM). - The coordinator sends a full read to one replica.
- The coordinator sends a digest reads to other replicas it needs for the quorum.
- If all digests match, no repair is needed.
- If any digest differs, the coordinator fetches a full read from that replica and compares timestamps/versions.
- The newest value is selected.
- The coordinator writes back(in-place) to any replicas that had stale data (a repair mutation).
In Cassandra 4.x, read repair can be blocking(default) or none(read_repair_chance=0). The former guarantees monotonic quorum reads at the cost of latency.
Read repair in Dynamo
- The coordinator contacts all replicas in the key's preference list(or the first
Nreachable nodes). - Each replica returns its value plus it's vector clock.
- The coordinator compares vector clocks to determine the latest version. If multiple versions exist, it returns them all to the client for resolution.
- The coordinator writes back(replicates) the latest version to every replica that had an older version. This includes replicas that missed the write due to being down.
Leaderless Replication in Practice
While all leaderless systems share the same foundational principles, their implementations vary in details and optimizations. Let's look at some of the popular ones. We've already discussed some details of Cassandra and Dynamo above. Below we'll understand some more details about these systems.
Apache Cassandra
Cassandra is the most popular and widely deployed leaderless database. Its design principles are operational simplicity, high write throughput and tunable consistency.
Tunable Consistency Levels
Cassandra offers a set of consistency levels that can be specified per query, allowing applications to fine-tune the balance between consistency, availability and latency. The most common levels are:
ONE/LOCAL_ONE: The coordinator waits for a response from one replica(in the same datacenter forLOCAL_ONE). This offers low latency and high availability but weak consistency. It is ideal for non-critical use-cases like analytics event tracking or updating counters.QUORUM/LOCAL_QUORUM: The coordinator waits for a majority of replicas(in the same datacenter forLOCAL_QUORUM). This provides a strong balance between consistency and availability. ForLOCAL_QUORUM, it provides strong consistency within a single datacenter, avoiding the high latency of cross-datacenter communication.ALL: The coordinator waits for all replicas to respond. This offers the strongest consistency guarantee but at the cost of availability and latency. If any replica is down, the write/read will fail. It is suitable for critical operations like financial transactions.
Cassandra Write Path
Cassandra's write performance is legendary, a direct result of its append only storage(LSM-trees) that avoid slows in-place updates. Here's a high-level overview of the write path:
- The client sends a write request to any node in the cluster, which acts as the coordinator.
- The coordinator immediately writes the data to an on-disk commit log (a WAL or write-ahead log) for durability.
- The data is written to an in-memory structure called a
Memtable. - The coordinator forwards the write to all relevant replica nodes.
- Once the required number of replicas (W) acknowledge the write, the coordinator responds to the client confirming success.
- Periodically or when a Memtable becomes full, its contents are flushed to a new immutable, on-disk file called an
SSTable(Sorted String Table).
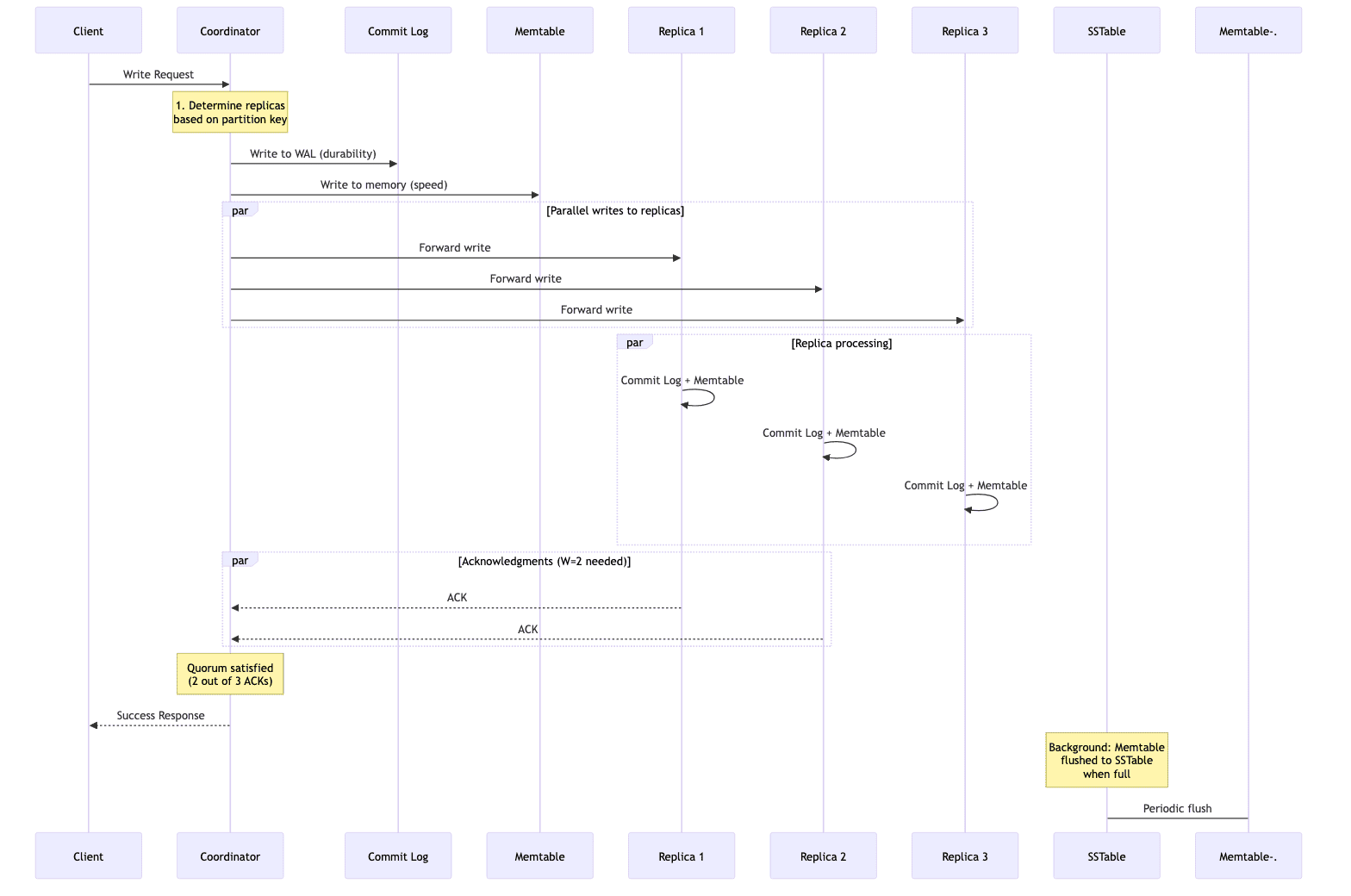
This ensures the writes are extremely fast as they primarily involve an append to a sequential log and an in-memory update.
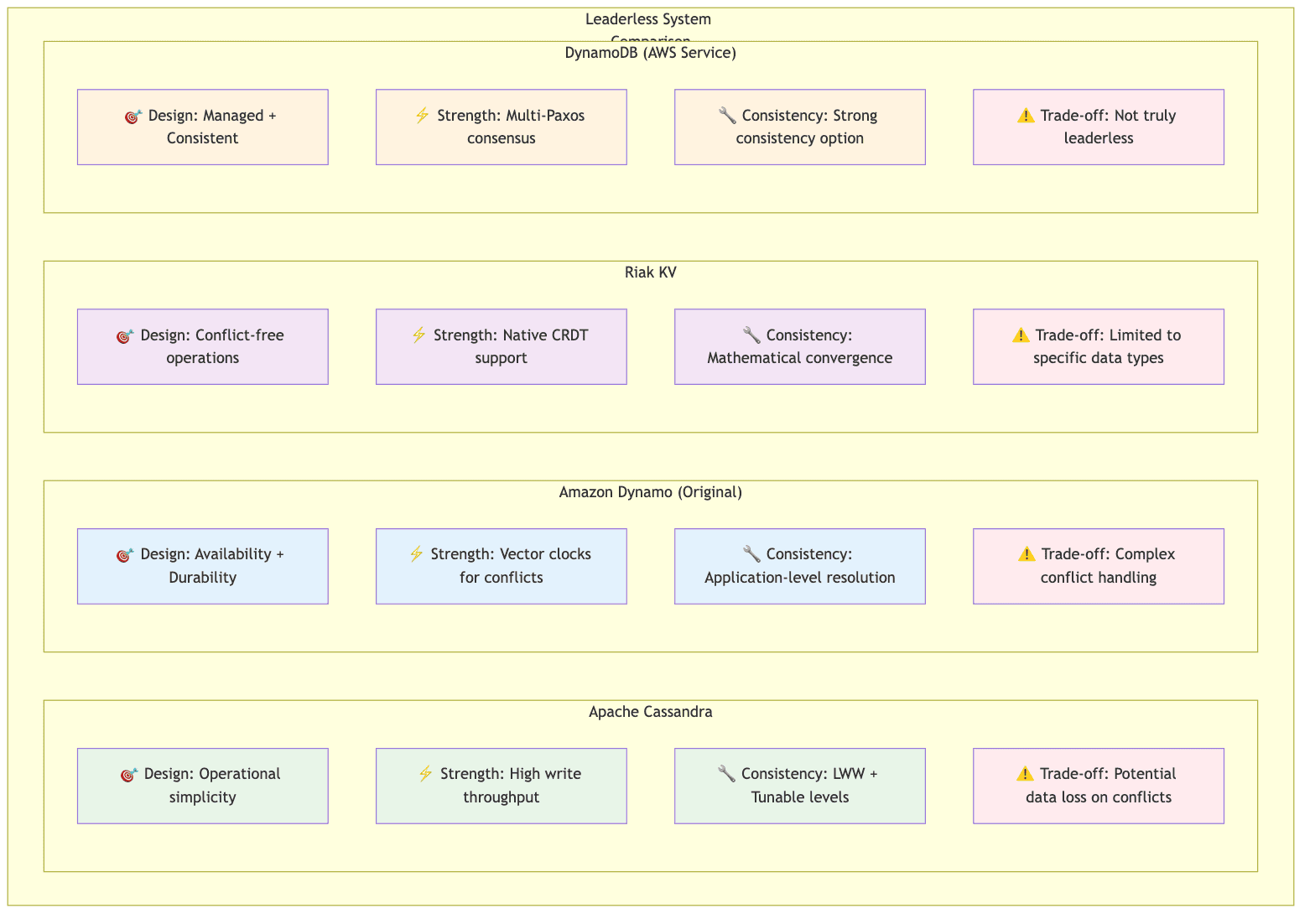
Amazon Dynamo and DynamoDB distinction
The original Amazon Dynamo paper laid the groundwork for the entire genre of leaderless databases. One of its key contributions was the use of version vectors or vector clocks to handle concurrent writes. Unlike Cassandra's LWW(Last Write Wins) approach, which relies on timestamps and can potentially lose a concurrent update, Dynamo used version vectors to detect when two clients concurrently write to the same key. Instead of discarding one write/update, Dynamo would keep both the conflicting versions and return them to the client for resolution. This pushes the responsibility of conflict resolution to the application layer. This is a more robust method for preventing data loss but increases application complexity.
It is critical to distinguish the original Dynamo paper from the AWS Service called Amazon DynamoDB. Amazon DynamoDB is not a leaderless system. While it is built on the principles of Dynamo such as partitioning and high-availability, its underlying replication mechanism is leader based, using the Multi-Paxos consensus algorithm. This allows DynamoDB to provide strong consistency guarantees, a feature not typically available in true leaderless systems.
Riak KV
Riak KV is another database inspired from the Dynamo paper. It features a ring of virtual nodes for improved load balancing and fault tolerance. The most significant innovation is its native support for Conflict-free Replicated Data Types (CRDTs).
CRDTs are specialized data structures such as counters, sets and flags that have mathematically provable properties allowing them to resolve concurrent updates automatically and correctly, without creating conflicting siblings. For ex. if two clients concurrently increment a CRDT counter, the system can merge these operations to arrive at the correct final sum. This moves the conflict resolution logic from the application layer to the database itself, simplifying application development.
Here we see the core design decisions for each of these leaderless systems. Dynamo's approach prioritizes availability and durability, pushing complexity to the application. Riak's CRDTs solve the problem elegantly within the database but is limited to specific data types. Cassandra's LWW is operationally simple and performant but carries a known risk of data loss from concurrent writes. All these choices reflect the trade-off between correctness and simplicity that is inherent in distributed systems design.
Conclusion
Leaderless replication is a powerful architectural pattern for building systems that require high availability, fault tolerance and scalability. The decentralized design eliminates single points of failure and allows the system to continue operating even in the face of node failures and network partitions. This comes at the cost of increased operational complexity, sophisticated repair mechanisms and the shift from strong, immediate consisteny to a more flexible, tunable consistency model.
Picking between a leader-based and leaderless system ultimately depends on the specific needs of the application. For systems where data integrity and transactional guarantees are non-negotiable, a leader-based approach may be more appropriate. But for those that prioritize uptime, scalability and the ability to handle massive write workloads, the leaderless model offers a powerful solution.
Designing highly available distributed systems requires careful architectural decisions and experienced engineers. I work with companies to design and scale fault-tolerant data infrastructure that meets their availability and consistency requirements. If you're building a team to support mission-critical systems, my hiring advisory services can help you find engineers with proven expertise in distributed systems and high-availability architectures.
I hope you liked reading this post. If you have any questions, feedback, corrections or suggestions, please feel free to leave a comment down below.
Until the next time! Happy Learning!
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.