
2024-06-07
Stream Processing with Apache Flink. Part-1
Introduction to Stream Processing, Apache Flink and the DataStream API

Stream Processing with Apache Flink. Part-1
This is a series of blog posts about Stream processing with Apache Flink. We'll dive into the concepts behind the Flink engine, creating streaming data pipelines, packaging and deploying Flink applications and how it integrates with external systems like Kafka, Snowflake and cloud providers.
Here is the entire series so far. I'll keep updating this as and when they're published:
- Stream Processing with Apache Flink. Part-1 (You're here)
- Stream Processing with Apache Flink. Part-2: DataStream Hands-on with Java
- Stream Processing with Apache Flink. Part-3: CDC to Iceberg Table
- Stream Processing with Apache Flink. Part-4: Datastream Enrichment
Contents
- 1. What is Stream Processing?
- 2. Dataflow Model
- 3. Flink Architecture
- 4. DataStream API
- 5. Time and Watermarks
- 6. Windows and Window Functions
- 7. Dealing with Late-arriving data
- 8. State Backends and Checkpointing
- Conclusion
1. What is Stream Processing?
Stream processing is the paradigm at work when you process unbounded data streams. It involves
continuous computation over this data as it arrives.
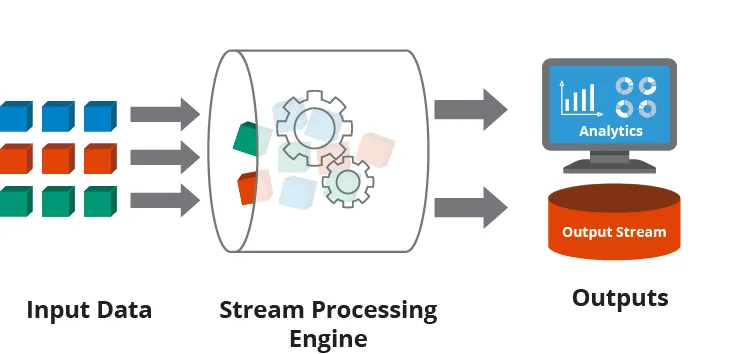
Source: Hazelcast
Data generally comes from:
- Message queues example: RabbitMQ, AWS SQS
- Distributed logs example: Apache Kafka, Apache Pulsar, AWS Kinesis
- Websockets
- Or even from continuous file uploads
The application responsible for processing this data as it arrives is called a Stream Processing
engine or a Stream processor.
Examples of Stream processors include: Kafka Streams, Apache Flink and Apache Beam.
2. Dataflow Model
Flink builds upon a lot of principles from Dataflow: a stream processing model created at Google which in turn follows the principles behind FlumeJava and Google Cloud Dataflow (derived from Google MillWheel).
Unlike traditional batch or micro-batch processing, it ensures that data is processed as it arrives
enabling immediate analysis and decision-making.
At the core of the dataflow model are notions of time, state and watermarks. We will discuss these later on
in this post.
3. Flink Architecture
Flink consists of two main types of processes: the JobManager and the TaskManager.
The Client or the driver sends a dataflow to the JobManager for execution.
A cluster can have multiple TaskManagers to execute the flink application, usually submitted
as a Java/Scala JAR. Resource management can be done via an external resource manager for example:
YARN, Kubernetes.
TaskManagers connect to JobManagers, register as workers and get work assigned to them. Communication between the job manager and the task managers is enabled by the Akka (open sourced fork now as Apache Pekko) framework. The communication between task managers is done at a lower level using Netty. The Flink application is submitted to the job manager as a dataflow graph.
There is a great blog on the Flink website that goes into their network stack in detail.
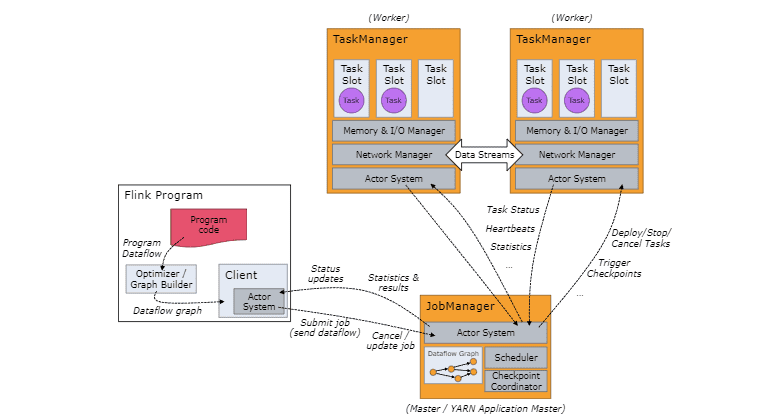
Source: Flink docs
3.1 Main components of a JobManager
- Resource Manager (YARN, Kubernetes, Standalone)
- Dispatcher (REST interface and WebUI)
- JobMaster (JobGraph execution manager; Each Flink job has its own JobMaster)
Note: For HA(Highly-available) production systems, multiple JobManagers are recommended where one
acts as a leader and the others as standby.
3.2 Main components of a TaskManager
They're the workers that execute the tasks of a dataflow. They buffer and exchange data streams with
other task managers of the cluster.
TaskManagers are made up of task slots. The number of task slots indicate the number of concurrent processing tasks.
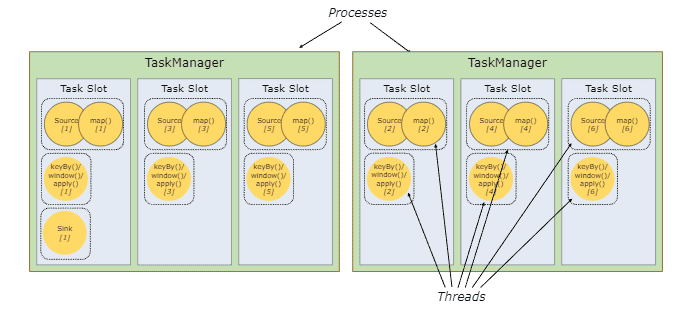
Source: Flink docs
4. DataStream API
Flink offers two main APIs for stream processing:
- DataStream API
- Table API
We'll be focusing on the DataStream API in this part. The Table API will be discussed in a later part of this series along with hands-on exercises.
The DataStream API is Flink's de-facto streaming API that can stream anything from basic primitive types (String, Long etc.) to composite types like Tuples, POJOs and Scala case classes.
The core components are:
- Sources
- Stateless and Stateful transformations
- Sinks
Full list of compatible Sources and Sinks can be found here.
4.1 Sources and Sinks
Sources are the input to a stream processing data pipeline that send continuous streams of data downstream to the dataflow graph through various transformations before it ends up in a sink.
Sinks are the output or the final destination for the data being processed by Flink. Common
examples of sinks are Kafka topics, persistent data-stores, data-lakes and/or object storage.
Flink offers a wide variety of sources including FileSource, KafkaSource and RMQSource as
well as their Sink counterparts.
A simple example of a Flink stream source and sink:
1List<Person> people = new ArrayList<>(); 2 3people.add(new Person("Dean", 38)); 4people.add(new Person("Sam", 34)); 5people.add(new Person("Mary", 62)); 6 7DataStream<Person> stream = env.fromData(people); 8 9// some transformations 10// ... 11 12 13// Sink to stdout 14stream.print(); 15 16env.execute(); 17
4.2 Transformations
Transformations are applied on a continuous stream of data from a source to produce the desired derived output before it can be sent to a sink for example: a persistent data store.
4.2.1 Stateless Transformations
There are 3 main stateless transformations:
- map()
- flatmap()
- filter()
These can be applied using a Java lambda or by implementing the interfaces for the respective functions.
1DataStream<Person> people = env.fromData(people); 2 3// Map as a lambda function 4// This creates a new DataStream<Person> by enriching a person with their address 5DataStream<PersonWithAddress> peopleWithAddress = people.map(person -> { 6 String address = addressMap.get(person.getId()); 7 return new PersonWithAddress(person.getId(), person.getName(), person.getAge(), address); 8}); 9 10// Implementing the Map Interface 11 12public class PersonWithJobTitleMapper extends RichMapFunction<PersonWithAddress, PersonWithJobTitle> { 13 14 @Override 15 public PersonWithJobTitle map(PersonWithAddress personWithAddress) throws Exception { 16 String jobTitle = jobTitleMap.get(personWithAddress.getId()); 17 return new PersonWithJobTitle( 18 personWithAddress.getId(), 19 personWithAddress.getName(), 20 personWithAddress.getAge(), 21 personWithAddress.getAddress(), 22 jobTitle 23 ); 24 } 25 26 @Override 27 public void open(OpenContext openContext) throws Exception { 28 super.open(openContext); 29 } 30} 31 32// This can now be applied to our previous DataStream 33DataStream<PersonWithJobTitle> peopleWithJobTitle = peopleWithAddress.map( 34 new PersonWithJobTitleMapper() 35); 36
Similarly, the flatmap() method can be implemented either as a lambda or by implementing the
RichFlatMapFunction or the FlatMapFunction interface.
4.2.2 Stateful Transformations
Transformations that maintain a state while processing each element are called Stateful.
Although state of a data pipeline or application can be managed outside flink, Flink provides some
nice support for managing state in a stream processing application.
State can be managed via:
- local Flink state is kept local to the machine that is processing it
- durable Fault-tolerant, automatically checkpointed at regular intervals
- vertically scalable embedded RocksDB instances that scale by adding more disk
- horizontally scalable distributed state across a Flink cluster
The keyBy() function is useful for partitioning streams so that all events with the same partition
can be processed together in a grouped fashion. Similar to the partitionBy in a Spark application.
1stream 2 .keyBy(record -> record.id) 3 .print() 4
All further transformations to this KeyedStream will be applied, grouped by that attribute.
To manage state within a Flink application, the DataStream API provides Rich Functions.
These are interfaces that implement the following methods:
open(Configuration c)called during operator initialization once. Use cases: load static data, open connection to an external serviceclose()getRuntimeContext()provides access to create and manage state including metrics
1// Example of working with Keyed State 2 3env.addSource(new EventSource()) 4 .keyBy(e -> e.getLocation()) 5 .flatMap(new Deduplicator()) 6 .print(); 7
The most commonly used state data structures provided by Flink are:
ValueState<T>Single value stateMapState<K, V>Map containing key-value pairsListState<T>List of multiple values
Example usage (from the Flink docs):
1public static class Deduplicator extends RichFlatMapFunction<Event, Event> { 2 ValueState<Boolean> keyHasBeenSeen; 3 4 @Override 5 public void open(Configuration conf) { 6 ValueStateDescriptor<Boolean> desc = new ValueStateDescriptor<>("keyHasBeenSeen", Types.BOOLEAN); 7 keyHasBeenSeen = getRuntimeContext().getState(desc); 8 } 9 10 @Override 11 public void flatMap(Event event, Collector<Event> out) throws Exception { 12 if (keyHasBeenSeen.value() == null) { 13 out.collect(event); 14 keyHasBeenSeen.update(true); 15 } 16 } 17} 18
If during the processing, you encounter a scenario where you need to clear the state for that key,
you can call the .clear() method on it.
1keyHasBeenSeen.clear() 2
4.3 Connected Streams
This covers use-cases where we have multiple streams that we need to combine and process together.
An example would be joining two streams.
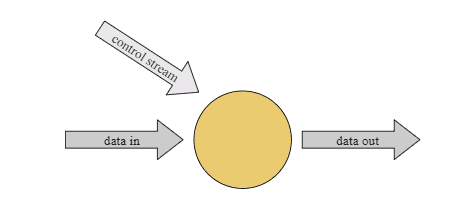
Source: Flink Docs
Flink has a RichCoFlatMap or RichCoMap and other functions for connected streams.
Example from the flink docs:
1public static class ControlFunction extends RichCoFlatMapFunction<String, String, String> { 2 private ValueState<Boolean> blocked; 3 4 @Override 5 public void open(Configuration config) { 6 blocked = getRuntimeContext() 7 .getState(new ValueStateDescriptor<>("blocked", Boolean.class)); 8 } 9 10 @Override 11 public void flatMap1(String control_value, Collector<String> out) throws Exception { 12 blocked.update(Boolean.TRUE); 13 } 14 15 @Override 16 public void flatMap2(String data_value, Collector<String> out) throws Exception { 17 if (blocked.value() == null) { 18 out.collect(data_value); 19 } 20 } 21} 22
Here the RichCoFlatMapFunction defines a function over 2 streams with values of type String.
We provide 2 flatmap functions as we cannot control how the elements will flow through the operator.
So we define a flatMap for either of the two elements from the streams.
It is important to note that Keyed Connected Streams must be partitioned in the same way.
5. Time and Watermarks
Flink has 3 notions of time:
- Event Time: Time at which the event was produced or created. Usually comes from the system producing the event.
For example: A Kafka Topic - Ingestion Time: Time at which the event is ingested into a Flink source
- Processing Time: Time at which a particular event is being processed by an operator
If we're using Event time, we need to tell Flink how to extract the Timestamp from our event.
This is done via the TimestampAssigner.
Watermarks are the threshold time that the processor should wait for a late event or an event
that occurred earlier.
Both the timestamp extractor and watermark generator are part of the WatermarkStrategy in Flink.
A WatermarkStrategy defines how to extract timestamp from a stream with a event time characteristic and
when and how to deal with late arriving events.
Flink provides some Watermark strategies out of the box that work for around 90% of the use-cases:
WatermarkStrategy.noWatermarks()WatermarkStrategy.forBoundedOutOfOrderness(Duration t)WatermarkStrategy.forMonotonousTimestamps()
1// Creating a watermark strategy 2 3DataStream<Event> stream = env.addData(collection); 4 5// some transformations 6// ... 7 8WatermarkStrategy<Event> strategy = WatermarkStrategy 9 .<Event>forBoundedOutOfOrderness(Duration.ofSeconds(10)) 10 .withTimestampAssigner((event, timestamp) -> event.getTimestamp()); 11 12DataStream<Event> streamWithWatermarkStrategy = stream 13 .assignTimestampAndWatermarks(strategy); 14
6. Windows and Window Functions
To do analytics or compute aggregates over unbounded data, we use window semantics to perform
these aggregations over bounded subsets.
Some use-cases of streaming analytics:
- number of page views on a landing page over 5 minutes
- number of sessions per user per week
- maximum purchase order every 10 minutes
Flink provides 2 principal abstractions when dealing with windowed analytics:
- Window Assigners
- Window Functions
6.1 Window Assigners
Flink provides several built-in window assigners:
- Tumbling windows: Fixed size windows with no overlaps
- Sliding windows: Fixed size windows with overlap
- Session windows: Windows that draw the session boundary after a specific time gap is observed
- Global window: Single window for all events. Reduces parallelism to 1
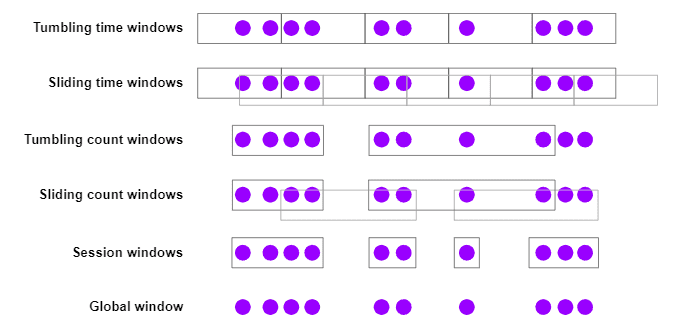
Source: Flink Docs
6.2 Window functions
Once events have been assigned to windows, Flink provides 3 main ways to process this data:
- As a batch, using a
ProcessWindowFunctionthat gets anIterable<T>with the window's contents - Incrementally, using
ReduceFunctionorAggregateFunctionwhich is called for every element assigned to the window - Combination of two. Pre-aggregate using Reduce or Aggregate and supply it as a batch to a Process function
An example from the Flink docs:
1DataStream<SensorReading> input = ...; 2 3input 4 .keyBy(x -> x.key) 5 .window(TumblingEventTimeWindows.of(Time.minutes(1))) 6 .process(new MyWastefulMax()); 7 8public static class MyWastefulMax extends ProcessWindowFunction< 9 SensorReading, // input type 10 Tuple3<String, Long, Integer>, // output type 11 String, // key type 12 TimeWindow> { // window type 13 14 @Override 15 public void process( 16 String key, 17 Context context, 18 Iterable<SensorReading> events, 19 Collector<Tuple3<String, Long, Integer>> out) { 20 21 int max = 0; 22 for (SensorReading event : events) { 23 max = Math.max(event.value, max); 24 } 25 out.collect(Tuple3.of(key, context.window().getEnd(), max)); 26 } 27} 28
This processes the contents of the window as a batch. Therefore, it receives an Iterable of the
type of the elements in the DataStream.
Important to note is that context is supplied to the process function that can be used to manage the state
of the Flink application.
This is the class definition the base Context that Flink provides:
1public abstract class Context implements java.io.Serializable { 2 public abstract W window(); 3 4 public abstract long currentProcessingTime(); 5 public abstract long currentWatermark(); 6 7 public abstract KeyedStateStore windowState(); 8 public abstract KeyedStateStore globalState(); 9} 10
Window state and global state provide a key-value store for per-key and per-window values.
7. Dealing with Late-arriving data
Late events are by default dropped in Flink applications.
However, an alternative is to collect them into another stream so we can process them later or trigger
downstream tasks associated with error handling for example: alerting.
The way this can be accomplished in Flink is via side-outputs.
An example to do this:
1OutputTag<Event> lateEvents = new OutputTag<Event>("lateEvents"){}; 2 3SingleOutputStreamOperator<Event> result = stream 4 .keyBy(event -> event.getLocation()) 5 .window(TumblingProcessingTimeWindows.of(Duration.ofSeconds(10))) 6 .sideOutputLateData(lateEvents) 7 .process(new SomeProcessingFunction()); 8 9// Now late events can be collected into a datastream 10DataStream<Event> lateEventsStream = result.getSideOutput(lateEvents); 11
8. State Backends and Checkpointing
The state managed by Flink can be thought of as a sharded key-value store across the nodes of the cluster.
It uses a state backend to store these k-v pairs.
There are 2 main types of state backends available in Flink:
- EmbeddedRocksDBStateBackend: Stores state in an embedded RocksDB instance on the local disk. It supports
full and incremental snapshots. - HashMapStateBackend: This is stored in-memory on the JVM heap. It only supports full snapshots.
Flink also takes persistent snapshots of all the state in every operator of a dataflow graph. It stores these
checkpoints on a durable, persistent file system. In the event of a failure, Flink can restore the state of the
application.
The location can be specified when defining the StreamExecutionEnvironment. It can be stored on:
FileSystem(recommended for production)JobManagerCheckpointStorageon the JVM heap in-memory (fine for testing only)
More information on how Flink performs snapshots can be found here.
Conclusion
Flink is true stream processing engine that makes it easy and fun working with streaming analytics.
I'm beginning my journey into Flink and love working with it so far. I'll be documenting my learnings here.
Beyond consulting, I help organizations scale their real-time data infrastructure from initial deployment to handling millions of events per second, and provide hiring advisory to help you find streaming engineers who can build and optimize Flink applications.
If you have any suggestions, comments or corrections, please drop a comment down below.
Stay tuned for the next blog post on Apache Flink.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.