
2024-06-14
Stream Processing with Apache Flink. Part-2
Hands-on with the Flink DataStream API using the Java client
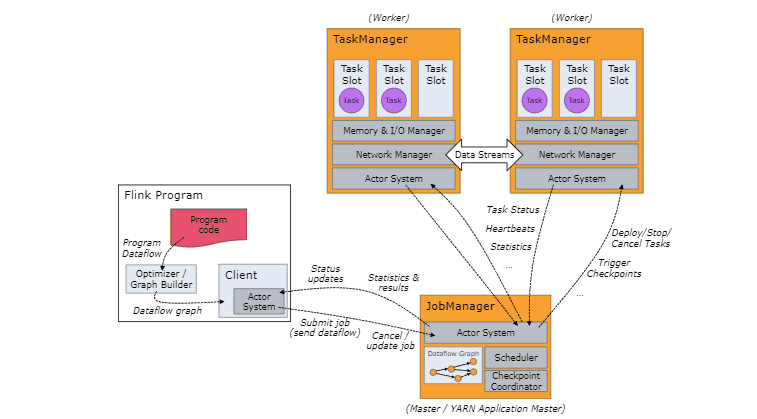
Stream Processing with Apache Flink. Part-2
This is a series of blog posts about Stream processing with Apache Flink. We'll dive into the concepts behind the Flink engine, creating streaming data pipelines, packaging and deploying Flink applications and how it integrates with external systems like Kafka, Snowflake and cloud providers.
In this post, we'll be creating a small data pipeline using the Flink java client to read from a CSV file and compute a running average per key.
We'll then simulate calculating averages over months and write it out as partitioned parquet files.
This is just a preview of the capabilities of Flink and the patterns that we discuss here should be coupled with best practices when running in production.
The codebase for this project can be found on github.
Here is the entire series so far. I'll keep updating this as and when they're published:
- Stream Processing with Apache Flink. Part-1
- Stream Processing with Apache Flink. Part-2: DataStream Hands-on with Java (You're here)
- Stream Processing with Apache Flink. Part-3: CDC to Iceberg Table
- Stream Processing with Apache Flink. Part-4: Datastream Enrichment
Contents
- Dataset Description
- Local Flink Cluster
- Dependencies
- Creating the data models
- Defining the Source and Sink
- Computing the Running Average
- Emulating total average over bounded stream
- Tying it all together
- Conclusion
Dataset Description
The dataset that we'll be using in this exercise, comes from Kaggle.
A preview of the dataset:
1Date,Open,High,Low,Close,Adj Close,Volume 21986-03-13,0.088542,0.101563,0.088542,0.097222,0.060055,1031788800 31986-03-14,0.097222,0.102431,0.097222,0.100694,0.062199,308160000 41986-03-17,0.100694,0.103299,0.100694,0.102431,0.063272,133171200 5
It has the following fields:
Date: Date of the recorded stock priceOpen: opening priceHigh: highest priceLow: lowest priceClose: closing priceVolume: total volume traded
We'll mostly be using the Date and Close fields but we'll read in all the values into our workflow.
In production, if you're using a subset of data from a streaming source like Kafka, it would make sense to only project the values that you'll be using in your processor/application.
Local Flink Cluster
We'll be using docker to spin up a local flink cluster. We'll mount the data directory where we have our stock price data so the taskmanagers can access the data.
1version: "2.2" 2 3services: 4 jobmanager: 5 image: flink:latest 6 ports: 7 - "8081:8081" 8 command: jobmanager 9 environment: 10 - | 11 FLINK_PROPERTIES= 12 jobmanager.rpc.address: jobmanager 13 volumes: 14 - ./data:/opt/data 15 16 taskmanager: 17 image: flink:latest 18 depends_on: 19 - jobmanager 20 command: taskmanager 21 scale: 1 22 environment: 23 - | 24 FLINK_PROPERTIES= 25 jobmanager.rpc.address: jobmanager 26 taskmanager.numberOfTaskSlots: 2 27 volumes: 28 - ./data:/opt/data 29
Dependencies
We're using Flink version 1.19.0 so we'll need compatible libraries.
Along with the flink-java package, we need the following as well:
flink-streaming-javaflink-connector-filesfor theFileSourceandFileSink.flink-parquetfor using theFileSinkto write our partitioned parquet files.flink-avroandparquet-avrobecause we use theAvroParquetWriter.forReflectRecord.
You can find the pom.xml with all dependencies here
Creating the data models
It's much more convenient to parse out lines of text from the CSV file into java objects. We'll create a StockPrice class to hold the data.
1public class StockPrice { 2 3 private String date; 4 private Double open; 5 private Double high; 6 private Double low; 7 private Double close; 8 private Integer volume; 9 10 11 public StockPrice(String date, Double open, Double high, Double low, Double close, 12 Integer volume) { 13 this.date = date; 14 this.open = open; 15 this.high = high; 16 this.low = low; 17 this.close = close; 18 this.volume = volume; 19 } 20 21 @Override 22 public String toString() { 23 return "StockPrice{" + 24 "date='" + date + '\'' + 25 ", open=" + open + 26 ", high=" + high + 27 ", low=" + low + 28 ", close=" + close + 29 ", volume=" + volume + 30 '}'; 31 } 32 33 public StockPrice(String line) { 34 String[] fields = line.split(","); 35 36 try { 37 this.date = fields[0]; 38 this.open = Double.parseDouble(fields[1]); 39 this.high = Double.parseDouble(fields[2]); 40 this.low = Double.parseDouble(fields[3]); 41 this.close = Double.parseDouble(fields[4]); 42 this.volume = Integer.parseInt(fields[5]); 43 } catch (NumberFormatException e) { 44 this.date = fields[0]; 45 this.open = Double.parseDouble(fields[1]); 46 this.high = Double.parseDouble(fields[2]); 47 this.low = Double.parseDouble(fields[3]); 48 this.close = Double.parseDouble(fields[4]); 49 this.volume = Integer.parseInt(fields[6]); 50 } 51 } 52 53 54 public StockPrice() { 55 } 56 57 // getters and setters 58 // ... 59} 60
We add a constructor to construct the object from a line in the CSV file.
The lines from the Kaggle dataset have some discrepancies to encourage data cleaning. Some lines have an extra comma in the second last field and therefore, we need to add an additional check in the constructor to catch a NumberFormatException for when we try to parse that empty field and create it from the next element in the array.
In production settings, you should not have such a brittle setup. Ideally, the data would be produced using some sort of data contract between the producer and the downstream consumers, with the schema enforced by using formats such as
AvroandProtobuf.
We also need some classes to store the intermediate state in the Flink application.
The first is a class to hold the count and total per key of the records being processed. This will be used in a KeyedProcessFunction our application for computing the emulated total monthly average.
1private static class AverageState { 2 3 Integer count; 4 Double total; 5 Long lastModified; 6 7 public AverageState(Integer count, Double total, Long lastModified) { 8 this.count = count; 9 this.total = total; 10 this.lastModified = lastModified; 11 } 12 } 13
The second class we need is for the date and average that we get from our processor before we write it into the sink. This'll become clearer as we move onto the subsequent sections.
1private static class MonthAverage { 2 3 String date; 4 Double average; 5 6 public MonthAverage(String date, Double average) { 7 this.date = date; 8 this.average = average; 9 } 10 11 @Override 12 public String toString() { 13 return "MonthAverage{" + 14 "date='" + date + '\'' + 15 ", average=" + average + 16 '}'; 17 } 18 } 19
Defining the Source and Sink
We'll be reading and writing our data from the local filesystem. The process for reading/writing from object stores for example: S3, GCS and Azure will be quite similar.
The data will be read in from a FileSource<String> and written out to a FileSink<MonthAverage> using the AvroParquetWriters.forReflectRecord.
The source:
1FileSource<String> source = FileSource 2 .forRecordStreamFormat(new TextLineInputFormat(), new Path("/opt/data/msft.csv")) 3 .build(); 4
If you want to monitor a directory continuously for incoming csv files, you can build a source like so:
1FileSource<String> source = FileSource 2 .forRecordStreamFormat(new TextLineInputFormat(), new Path("/opt/data/msft.csv")) 3 .monitorContinuously(Duration.ofSeconds(10)) 4 .build(); 5
And the sink can be defined like so:
1FileSink<MonthAverage> sink = FileSink 2 .forBulkFormat(new Path("/opt/data/out"), 3 AvroParquetWriters.forReflectRecord(MonthAverage.class)) 4 .withBucketAssigner(new BucketAssigner<MonthAverage, String>() { 5 @Override 6 public String getBucketId(MonthAverage monthAverage, Context context) { 7 DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd"); 8 return String.valueOf(LocalDate.parse(monthAverage.date, formatter).getYear()); 9 } 10 11 @Override 12 public SimpleVersionedSerializer<String> getSerializer() { 13 return null; 14 } 15 }) 16 .build(); 17
Computing the Running Average
Creating a KeyedStream
Now that we have the FileSource<String>, we can create a Flink DataStream from it.
1DataStream<String> stream = env 2 .fromSource(source, WatermarkStrategy.noWatermarks(), "msft-source"); 3
We have not set the watermark strategy as we will discuss this in later posts in this series. For the scope of this example, we have set it to noWatermarks().
The CSV file we've created the stream from, has a header line as well that we need to filter out. Since we know that the header starts with the date field, we can simply filter the stream to remove lines that start with this keyword. Next, we'll parse each line from this stream into the StockPrice class that we'd created earlier.
1DataStream<StockPrice> stockStream = stream 2 .filter(line -> !line.toLowerCase().startsWith("date")) 3 .map(new StockPriceMapper()); 4
The aim of our example is to compute a running average per month from our stream.
The way we would do this for ex. in a database would be to group by the month from the date field, and compute the average over the grouped values. However, Flink is a distributed processing engine and different subsets of the data would go to different task managers and subsequently to different tasks to be executed. We need a way to guarantee that the records belonging to the same month end up on the same task so we can compute the average over the values.
In an engine like Spark, we would repartition the dataframe by the key, in Flink we use the keyBy() method on the stream to convert a DataStream<T> into a KeyedStream<V, K>.
Since we need the month as the key for our stream, we can do it like so:
1KeyedStream<StockPrice, String> keyedStream = stream 2 .keyBy( 3 record -> { 4 DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd"); 5 return LocalDate.parse(record.getDate(), formatter).withDayOfMonth(1).toString(); 6 } 7 ); 8
We parse the date of type String into a java.time.LocalDate and then set it to the first day of the month. This ensures that all records from the same month and year have the same date.
Running average using KeyedProcessFunction
Once we have a keyed stream, we need to create a stateful processor that tracks the count and sum of all the numbers in the stream so that we can compute the running average and emit it per key.
The KeyedProcessFunction<K, V, OUT> has 3 main methods that can be implemented:
processElement()open()onTimer()
Since it is keyed, we can use a state object from Flink to store values that can be used in subsequent calls to this function. For this example, we'll use the org.apache.flink.api.common.state.MapState to store a key-value pair. The key would be the date of type String and the value would be a tuple of the running count and sum: Tuple2<Integer, Double>.
1public class AveragePerMonthProcessFunction extends 2 KeyedProcessFunction<String, StockPrice, Tuple2<String, Double>> { 3 private MapState<String, Tuple2<Integer, Double>> state; 4 5 @Override 6 public void processElement(StockPrice stockPrice, 7 KeyedProcessFunction<String, StockPrice, Tuple2<String, Double>>.Context context, 8 Collector<Tuple2<String, Double>> collector) throws Exception { 9 10 String key = context.getCurrentKey(); 11 12 if (state.contains(key)) { 13 Tuple2<Integer, Double> values = state.get(key); 14 Integer newCount = values.f0 + 1; 15 Double newSum = values.f1 + stockPrice.getClose(); 16 state.put(key, new Tuple2<>(newCount, newSum)); 17 collector.collect(new Tuple2<>(key, newSum / newCount)); 18 } else { 19 state.put(key, new Tuple2<>(1, stockPrice.getClose())); 20 collector.collect(new Tuple2<>(key, stockPrice.getClose())); 21 } 22 23 } 24 25 @Override 26 public void open(OpenContext openContext) throws Exception { 27 state = getRuntimeContext().getMapState(new MapStateDescriptor<>("runningCountSum", 28 TypeInformation.of(new TypeHint<String>() { 29 }), 30 TypeInformation.of(new TypeHint<Tuple2<Integer, Double>>() { 31 }))); 32 } 33 } 34
- We declare the
MapStatewith the required types - The state is initialised from the
open()method as it receives the runtime context from Flink. This would then be available across all invocations of the operator. - In the
processElementmethod, we:- Get the current key from the context (we have a keyed stream)
- If we already have state for the key, we update the count with
oldCount + 1and the sum witholdSum + stockPrice.getClose(). - If its a key we haven't see before, update the map state with count as 1 and sum set to the closing price for the current record.
- In either of the two cases, we emit it (
.collect())
Emulating total average over bounded stream
To compute the total average over the bounded stream, we can make some slight changed to our keyed process function.
We have access to the Flink context via our processElement() method, which can create an event time timer to execute the onTimer() method of the KeyedProcessFunction.
The method for this would look like this:
1@Override 2 public void processElement(StockPrice stockPrice, 3 KeyedProcessFunction<String, StockPrice, Tuple2<String, Double>>.Context context, 4 Collector<Tuple2<String, Double>> collector) throws Exception { 5 6 String key = context.getCurrentKey(); 7 Long lastModified = context.timestamp(); 8 9 if (state.contains(key)) { 10 AverageState current = state.get(key); 11 Integer newCount = current.count + 1; 12 Double newSum = current.total + stockPrice.getClose(); 13 state.put(key, new AverageState(newCount, newSum, lastModified)); 14 } else { 15 state.put(key, new AverageState(1, stockPrice.getClose(), lastModified)); 16 } 17 18 // 5 seconds to check 19 context.timerService().registerEventTimeTimer(lastModified + 5000); 20 21 } 22
Here we reset the timer if we encounter a record with the same key (date) in our case. We then update the timer to the current modified timestamp plus 5 seconds. This implies that if we do not see a record with this key in 5 seconds, we will execute the onTimer() method of this function.
The onTimer() method can be used to emit the average for that key from the operator.
1@Override 2 public void onTimer(long timestamp, 3 KeyedProcessFunction<String, StockPrice, Tuple2<String, Double>>.OnTimerContext ctx, 4 Collector<Tuple2<String, Double>> out) throws Exception { 5 String key = ctx.getCurrentKey(); 6 AverageState current = state.get(key); 7 8 if (timestamp >= current.lastModified + 5000) { 9 out.collect(new Tuple2<>(key, current.total / current.count)); 10 } 11 } 12
Tying it all together
Finally, we apply the operator to our keyed stream and sink the running average to the console, and the total average can be stored as partitioned parquet files using our FileSink.
1// running average 2keyedStream 3 .process(new AveragePerMonthProcessFunction()) 4 .print(); // to stdout 5 6 7// Emulated total average per month to partitioned parquet files 8keyedStream 9 .process(new TotalAverageMonthProcessFunction()) 10 .map(record -> new MonthAverage(record.f0, record.f1)) 11 .sinkTo(sink); // to the FileSink we'd created earlier 12
Conclusion
Flink's DataStream API is a really powerful tool for fast and reliable stream processing applications. In the subsequent posts, we'll dive into the Table API before we discuss how to operationalize and deploy Flink applications to production.
I've been trying out Flink for real-time analytical workloads for fun and learning.
If you or your company are doing real-time analytics at scale, please do reach out as I'd love to discuss about it. Beyond implementation, I also help companies scale their data and AI platforms from proof-of-concept to production, and provide hiring advisory to build teams capable of managing stream processing at scale.
If you have any suggestions, comments or corrections, please drop a comment down below.
Stay tuned for the next blog post on Apache Flink.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.