
2025-04-22
Stream Processing with Apache Flink. Part-4
Enriching a stream using an external database with Apache Flink

Stream Processing with Apache Flink. Part-4: Datastream Enrichment
This is a series of blog posts about Stream processing with Apache Flink. We'll dive into the concepts behind the Flink engine, creating streaming data pipelines, packaging and deploying Flink applications and how it integrates with external systems like Kafka, Snowflake and cloud providers.
Here is the entire series so far. I'll keep updating this as and when they're published:
- Stream Processing with Apache Flink. Part-1
- Stream Processing with Apache Flink. Part-2: DataStream Hands-on with Java
- Stream Processing with Apache Flink. Part-3: CDC to Iceberg Table
- Stream Processing with Apache Flink. Part-4: Datastream Enrichment (You're here)
Contents
- Introduction
- Infrastructure setup
- Producing orders data to Kafka
- Populating the lookup table
- Enriching the orders stream
- Conclusion
Introduction
Enrichment is a common operation in stream processing where you augment your streaming data with additional information from other sources.
These sources can be databases, external APIs, machine learning models or even other streams.
In this post, we'll explore a general approach to enrichment in Apache Flink using a simple example of enriching orders with customer information from a database. We'll use Kafka as the source of our orders and PostgreSQL as the database for customer information.
For this post, you should have a basic understanding of Apache Flink and Kafka. You can go over the previous posts in this series for a quick refresher.
All code for this post is available in the Github repository. Please consider giving it a star if you find it useful.
Infrastructure setup
We'll be using the following components:
- Docker
- Kubernetes
- kubectl
- Kafka
- Postgres
- Flink Kubernetes Operator
To setup the required infrastructure, you can refer to the previous post where we setup the infrastructure for the CDC pipeline. The accompanying code along with a handy Makefile and kubernetes manifests are available in the Github repository. All our data infrastructure is running on a local Kubernetes cluster using Docker Desktop.
Producing orders data to Kafka
Orders schema
We'll be simulating a stream of customer orders and producing them to a Kafka topic. The orders will be in JSON format and will have the following schema:
1{ 2 "customer_id": "int", 3 "order_id": "int", 4 "product_id": "int", 5 "created_at": "string", 6 "status": "string", 7 "payment_method": "string", 8 "amount": "float" 9} 10
Creating the Kafka topics
We'll create 2 kafka topics. One as a source topic for the orders and another as a sink topic for the enriched orders. To create the topics, run the following command:
1make setup-topics 2
This will create the orders and enriched-customer-orders topics.
Orders producer
We'll be using a simple Python producer to generate random orders and produce them to the orders topic. The producer is available under the scripts/producer directory.
It expects the following arguments:
--bootstrap_servers: The Kafka bootstrap server. This is the address of the Kafka broker.--topic: The topic to produce the orders to. This should be theorderstopic.--num_messages: The number of messages to produce. This is the number of orders to generate.--wait_time_ms: The wait time between messages in milliseconds. This is the time to wait between producing each order.
The orders are produced in the JSON format.
1def _generate_customer_data(self) -> Dict[str, Any]: 2 _customer_id = self._customer_id_start + 1 3 self._customer_id_start += 1 4 return { 5 "customer_id": _customer_id, 6 "order_id": random.randint(1000, 9999), 7 "product_id": random.randint(1000, 9999), 8 "created_at": datetime.now().isoformat(), 9 "status": random.choice(["pending", "completed", "failed"]), 10 "payment_method": random.choice(["credit_card", "paypal", "bank_transfer"]), 11 "amount": round(random.uniform(10.0, 500.0), 2), 12 } 13
Deploying the producer
We'll be deploying the producer as a Kubernetes job. The manifest for the job is available at k8s/producer-job.yml. The producer is packaged as a Docker image and optionally pushed to Docker Hub.
1apiVersion: batch/v1 2kind: Job 3metadata: 4 name: orders-producer 5 labels: 6 app: orders-producer 7spec: 8 template: 9 metadata: 10 labels: 11 app: orders-producer 12 spec: 13 containers: 14 - name: orders-producer 15 image: abyssnlp/orders-producer:0.1 16 imagePullPolicy: IfNotPresent 17 restartPolicy: Never 18 backoffLimit: 0 19
To deploy the producer on your local Kubernetes cluster, run the following command:
1make deploy-producer-job docker_username=abyssnlp # replace with your docker username 2
This will build the producer Docker image and deploy the manifest. In production, you can use the github hash as the image tag to ensure image versioning and immutability.

I've set the number of producer messages to 400 in the Dockerfile. You can change this number to experiment further.
After the job executes, you should see the messages in the orders topic. If you've followed along from the previous post, I provide manifests to deploy a Kafka UI to visualize the messages in the topic.
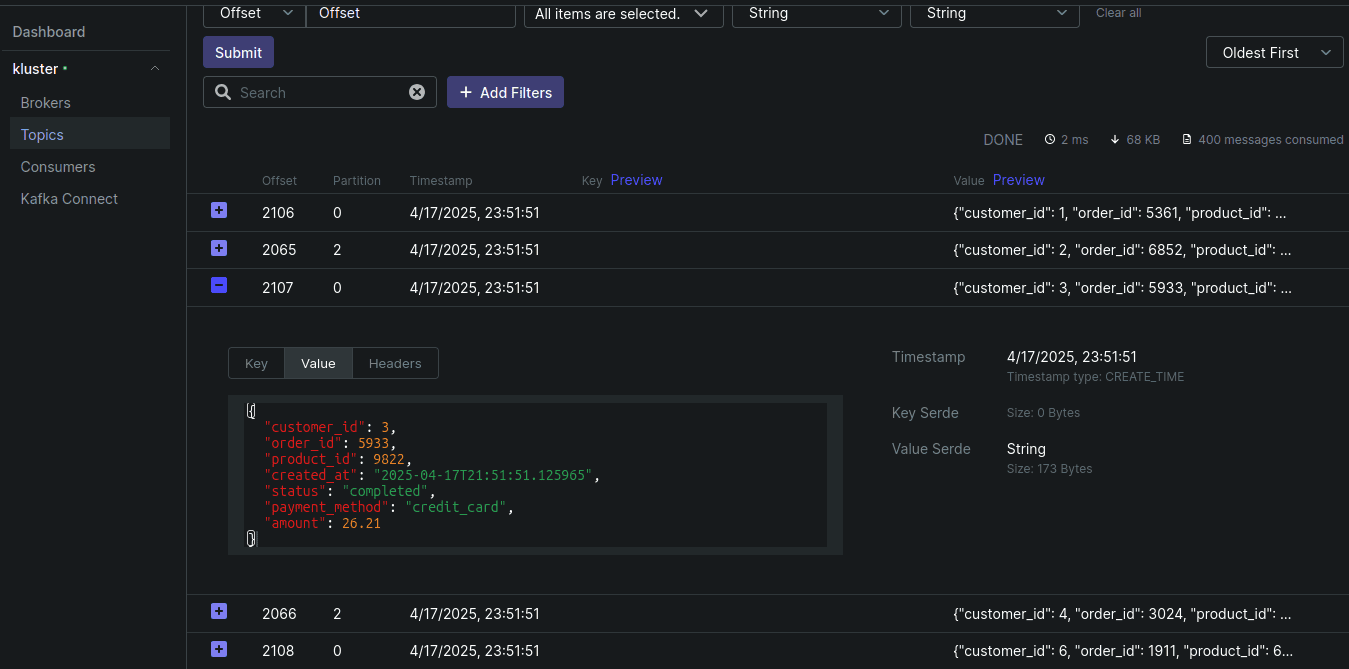
Populating the lookup table
Let's populate the lookup table with some customer data that we'll use to enrich the orders. We'll be using a PostgreSQL database deployed on Kubernetes for this. You can refer to the helm chart values here to deploy the database locally as well.
Customer table schema
The lookup table will have the following schema:
1id SERIAL PRIMARY KEY, 2name VARCHAR(100) NOT NULL, 3age INTEGER NOT NULL, 4address TEXT NOT NULL, 5created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP 6
We'll use the id field to lookup the customer information from this table. We can also create an index on the id field to speed up the lookups.
Inserting customer data
To populate the customer table, we'll use a simple Python script that connects to the PostgreSQL database and inserts random customer data. The customer data is generated using the Faker library. The script is available under the scripts/lookup directory.
It expects the following arguments:
--host: The database host. This is the address of the PostgreSQL database. As we're using Kubernetes, this should be the service name of the PostgreSQL database.--port: The database port. This is the port of the PostgreSQL database. Defaults to5432.--user: The database user. This is the user to connect to the PostgreSQL database.--password: The database password. This is the password to connect to the PostgreSQL database.--dbname: The database name. This is the name of the PostgreSQL database.--schema: The schema name. This is the name of the schema in the PostgreSQL database. Defaults topublic.--num-records: The number of records to insert. This is the number of customers to generate.
The script generates random customer data and issues an insert statement for each customer. The script exits once we've inserted the specified number of records.
1 def generate_and_insert_data(self, num_records: int): 2 try: 3 self.cursor.execute( 4 f"TRUNCATE TABLE {self.schema}.customers RESTART IDENTITY;" 5 ) 6 self.conn.commit() 7 8 insert_query = f""" 9 INSERT INTO {self.schema}.customers (name, age, address, created_at) 10 VALUES (%s, %s, %s, %s) 11 """ 12 13 for i in range(1, num_records + 1): 14 name = self.faker.name() 15 age = self.faker.random_int(min=18, max=80) 16 address = self.faker.address().replace("\n", ", ") 17 created_at = datetime.now() 18 self.cursor.execute(insert_query, (name, age, address, created_at)) 19 20 if i % 100 == 0 or i == num_records: 21 self.conn.commit() 22 self.logger.info(f"Inserted {i} records into the database.") 23 24 self.logger.info("All records inserted successfully.") 25 except Exception as e: 26 self.logger.error(f"Error inserting data: {e}") 27 self.conn.rollback() 28 raise 29
Deploying the lookup script
Similar to the producer, we'll be deploying the lookup script as a Kubernetes job. The manifest for the job is available at k8s/lookup-table-job.yml. It is also packaged as a Docker image.
1apiVersion: batch/v1 2kind: Job 3metadata: 4 name: lookup-table 5 labels: 6 app: lookup-table 7spec: 8 template: 9 metadata: 10 labels: 11 app: lookup-table 12 spec: 13 containers: 14 - name: lookup-table 15 image: abyssnlp/customers-lookup:0.1 16 imagePullPolicy: IfNotPresent 17 restartPolicy: Never 18 backoffLimit: 0 19
To deploy the lookup script on your local Kubernetes cluster, run the following command:
1make deploy-lookup-job docker_username=abyssnlp # replace with your docker username 2
I've set the number of records to 400 to match the number of orders produced. This is mostly because we want to generate customer data for the customer ids that are present in the orders topic.
You can connect to the Postgres database using a SQL client of your choice, to see the generated customer data. I prefer the SQLTools extension in VS Code.
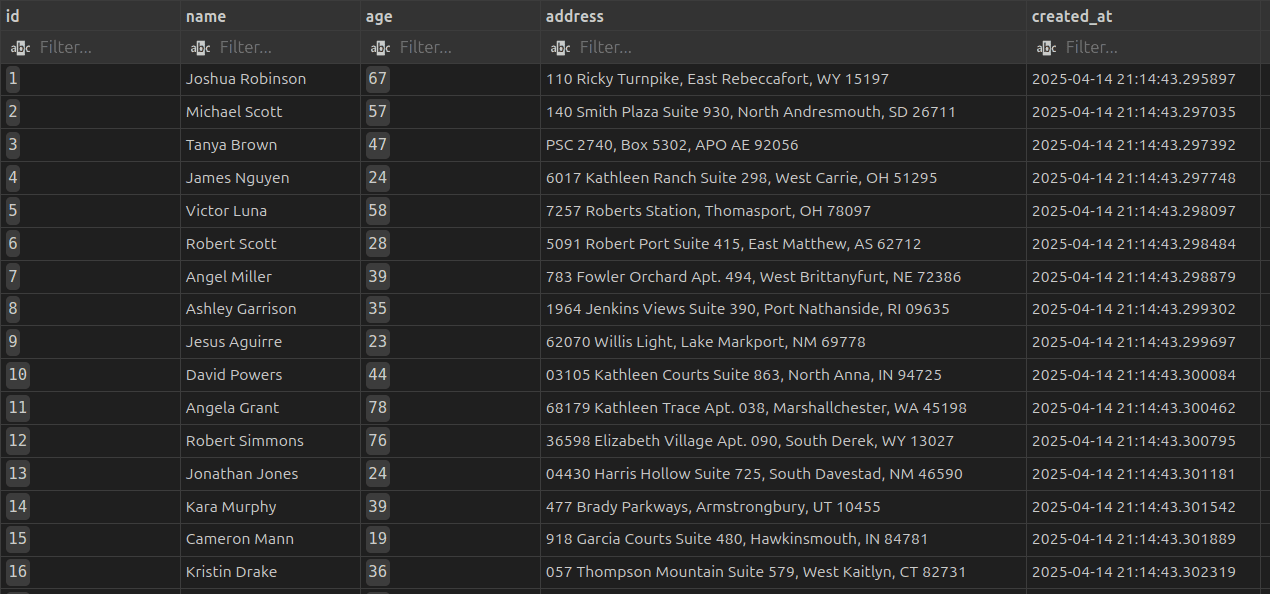
Enriching the orders stream
Now that we have the orders topic and the customers table populated, we can start enriching the orders stream with customer information.
Enrichment Options
Some common options for enriching streams in Flink are:
-
Synchronous enrichment: This is the simplest form of enrichment where you perform a synchronous lookup for each record in the stream. This can be done using the
RichMapFunctionorProcessFunctionin Flink. However, this can be slow as it blocks the stream until the lookup is complete. This is not recommended for high throughput scenarios. -
Broadcast enrichment: If the lookup table is small enough to fit in memory, you can use the broadcast state pattern to enrich the stream. This broadcasts the lookup table to all instances of the operator and allows you to perform lookups in memory. This is the recommended approach for small lookup tables as it is fast and does not require any external calls.
-
Asynchronous enrichment: This is a more advanced form of enrichment where you perform an asynchronous lookup for each record in the stream. This can be done using the
RichAsyncFunctionin Flink. This is the recommended approach for high throughput scenarios as it allows you to perform lookups in parallel and does not block the stream. We will be using this approach in this post.
Enriching with RichAsyncFunction
We'll be using the RichAsyncFunction to perform the lookups. This allows us to perform asynchronous lookups for each record without blocking the stream.
We'll also be using HikariCP for connection pooling to the PostgreSQL database. This allows us to reuse connections and improve performance. This is because creating a new connection for each lookup involves TCP handshakes, authentication and other overheads. HikariCP creates a pool of connections and reuses them for each lookup. For high throughput scenarios, this is a must.
The RichAsyncFunction interface contains the asyncInvoke method which is called for each record in the stream. This method takes the input record and a ResultFuture object which is used to complete the result of the asynchronous operation.
1@Override 2public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception { 3 CompletableFuture.supplyAsync(new Supplier<String>() { 4 @Override 5 public String get() { 6 try { 7 JsonNode node = objectMapper.readTree(input); 8 int customerId = node.get("customer_id").asInt(); 9 10 try (Connection conn = dataSource.getConnection(); 11 PreparedStatement stmt = conn.prepareStatement( 12 "SELECT * from customers where id = ?" 13 )) { 14 stmt.setInt(1, customerId); 15 try (ResultSet rs = stmt.executeQuery()) { 16 if (rs.next()) { 17 ObjectNode enrichedNode = (ObjectNode) node; 18 enrichedNode.put("customer_name", rs.getString("name")); 19 enrichedNode.put("customer_age", rs.getString("age")); 20 enrichedNode.put("customer_address", rs.getString("address")); 21 enrichedNode.put("customer_created_at", rs.getTimestamp("created_at").toString()); 22 return objectMapper.writeValueAsString(enrichedNode); 23 } 24 } 25 } 26 return objectMapper.writeValueAsString(defaultCustomerEnriched(node)); 27 } catch (Exception e) { 28 logger.error("Error in async enrichment: {}", e.getMessage()); 29 return input; 30 } 31 } 32 }, executorService).thenAccept(result -> { 33 resultFuture.complete(Collections.singleton(result)); 34 }); 35} 36
To use this function, we need to create an async datastream operator. This is done by wrapping the Kafka source with the AsyncDataStream operator. This operator takes the input stream and applies the async function to each record in the stream. We can also specify the maximum number of concurrent requests to the async function. This is useful to limit the number of concurrent requests to the database and avoid overwhelming it. I've set this to 100.
1DataStream<String> enrichedStream = AsyncDataStream.orderedWait( 2 stream, 3 new CustomerEnrichment(postgresUrl, postgresUser, postgresPassword), 4 5000, 5 TimeUnit.MILLISECONDS, 6 100 7); 8
We'll produce the enriched stream to the enriched-customer-orders topic. The data is produced in JSON format.
1 enrichedStream.sinkTo( 2 KafkaSink.<String>builder() 3 .setBootstrapServers(kafkaBootstrapServers) 4 .setRecordSerializer(KafkaRecordSerializationSchema.builder() 5 .setTopic(kafkaEnrichedTopic) 6 .setValueSerializationSchema(new SimpleStringSchema()) 7 .build()) 8 .build() 9); 10
Deploying the Flink application
We'll be deploying the Flink application using the Flink kubernetes operator. We'll package it as a docker image and deploy the manifest. The manifest is available at k8s/deploy.yml. The environment variables are mounted from a Kubernetes secret. To deploy the secrets:
1make setup-secrets 2
And to run the Flink application:
1make run-flink-enrichment docker_username=abyssnlp # replace with your docker username 2
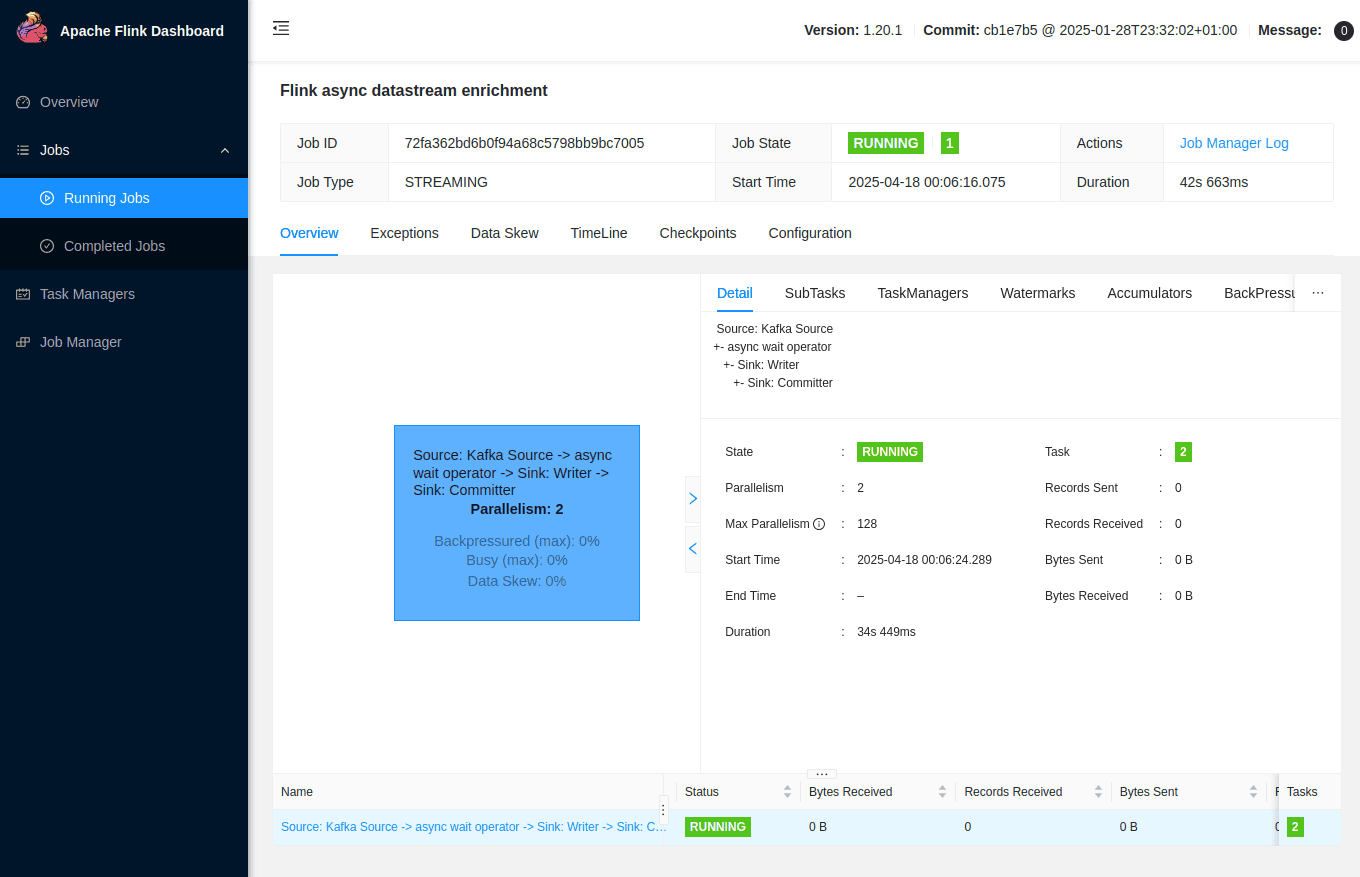
Once the application is running, you can inspect the Flink UI to see the job status and the metrics.
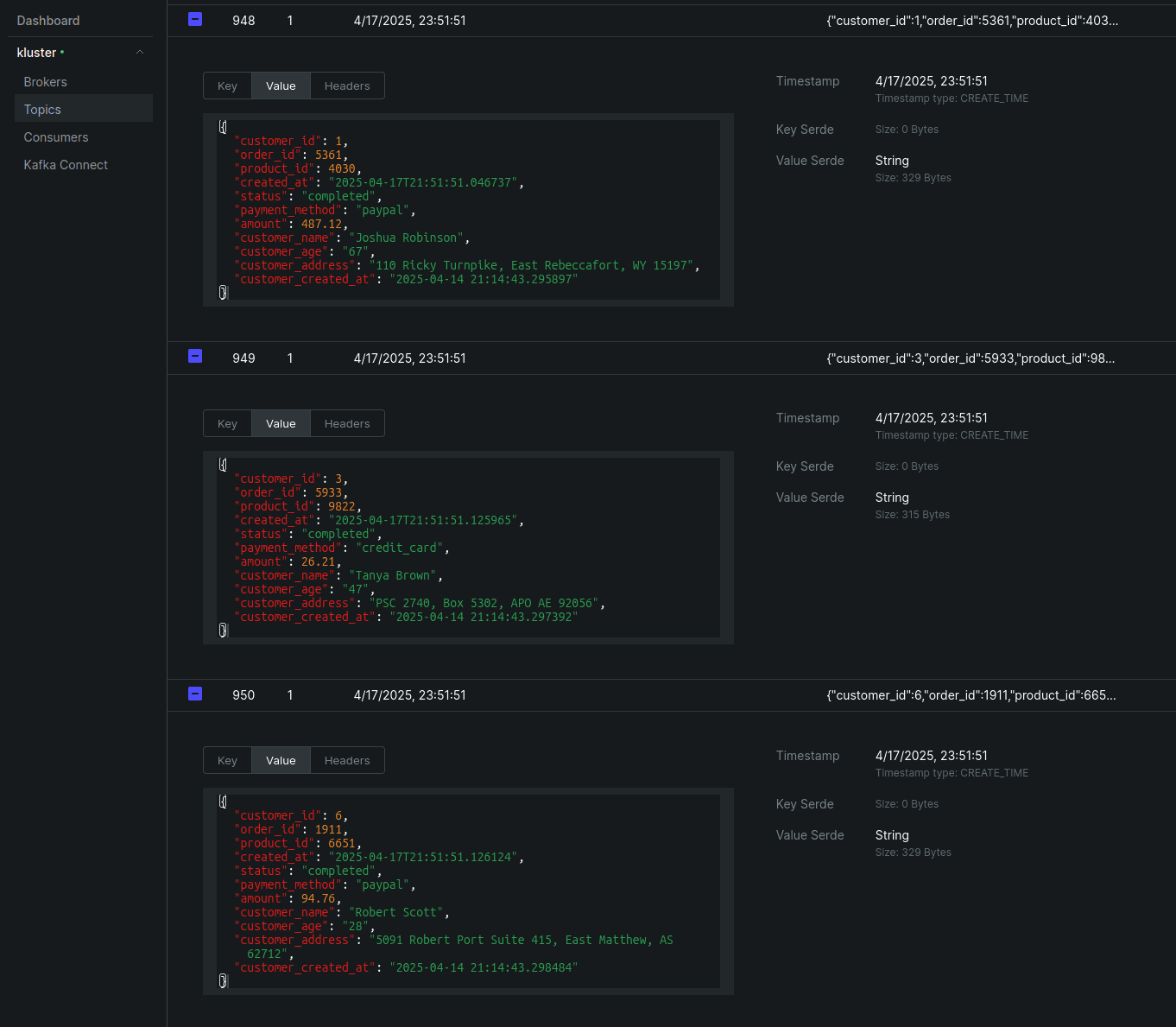
You can also check the enriched-customer-orders topic to see the enriched orders using the Kafka UI.
Conclusion
In this post, we explored how to enrich a stream of orders with customer information from a PostgreSQL database using Apache Flink. We used the RichAsyncFunction to perform asynchronous lookups and HikariCP for connection pooling. We also deployed the application using the Flink Kubernetes operator.
This is a simple example of how to enrich a stream with external data from a database. In real-world scenarios, you might run into scenarios where you use an external API or machine learning models for enrichment. The same principles apply, but you might need to handle additional complexities like authentication, rate limiting and error handling.
Implementing stream enrichment patterns with Flink is just the beginning. I help companies build and scale production-ready streaming platforms that handle complex enrichment, aggregations, and real-time analytics at scale. If you need to strengthen your streaming engineering team, my hiring advisory services can help you find engineers skilled in Flink, Kafka, and distributed stream processing.
If you found this post useful or have any questions, advise, feedback or remarks, please feel free to drop a comment below. I would love to hear from you.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.